AI/ML●●●Banger
Paper Lantern – improving Autoresearch with research knowledge
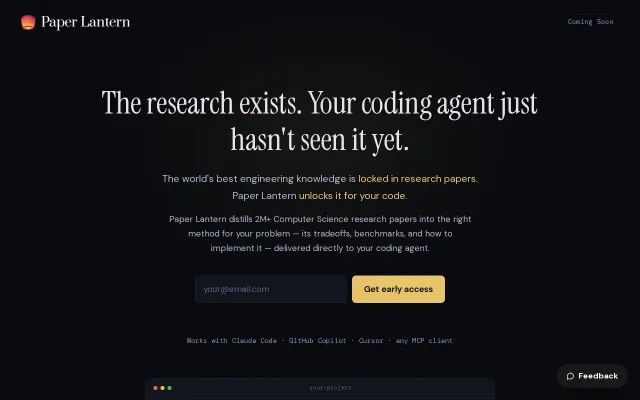
Coding agents miss research knowledge; this surfaces 2M+ papers with benchmarks.
Big BrainDark Horse
paperlantern
221mo ago
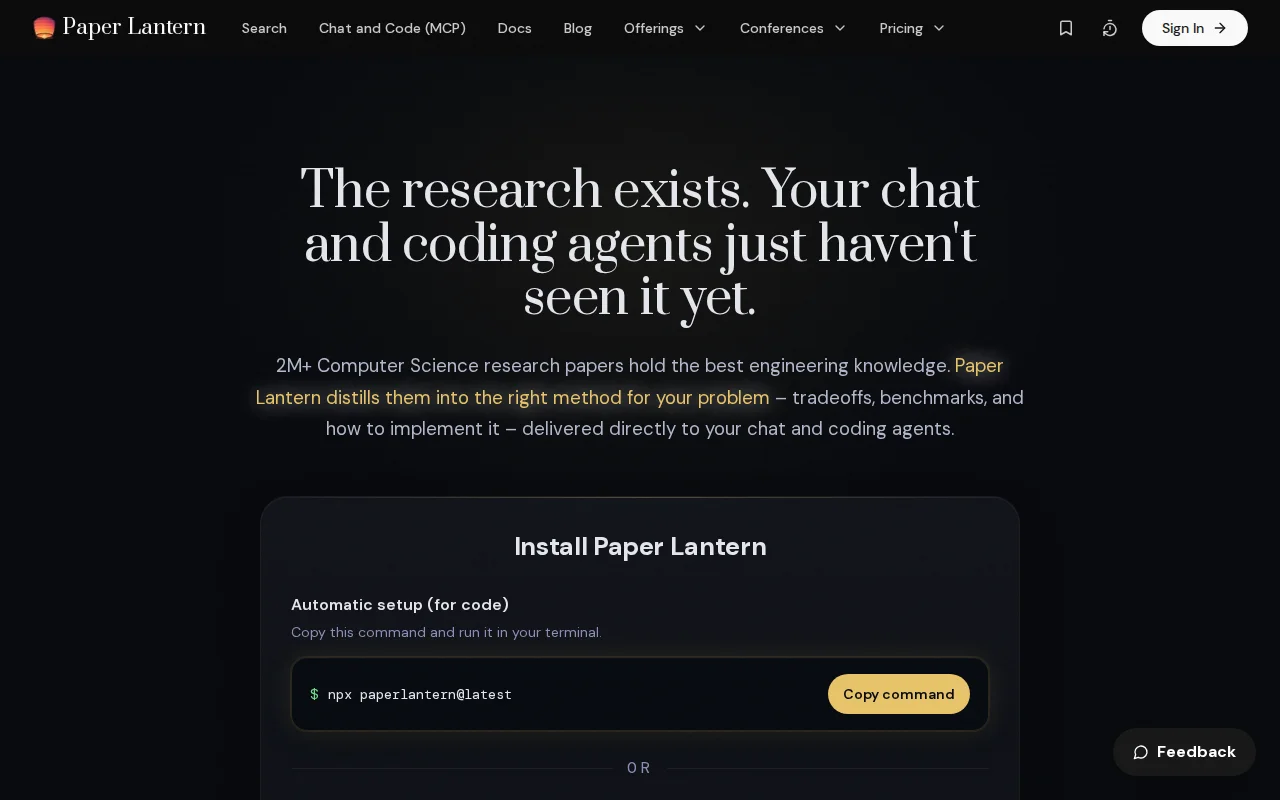
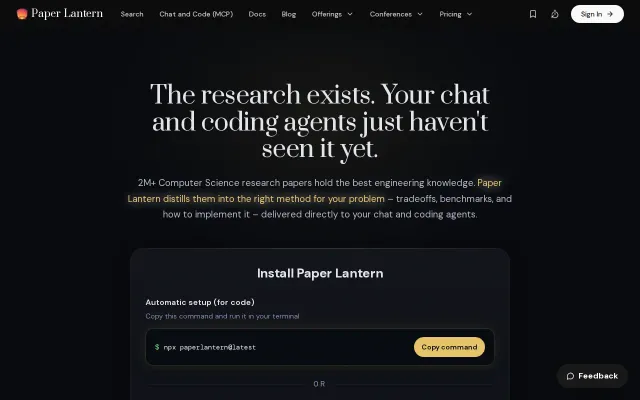
Coding agents search Stack Overflow; this serves them peer-reviewed techniques with benchmarks.
Developers using AI coding assistants (Cursor, Claude, etc.)
Continue.dev · Sourcegraph Cody
We had previously shown that this helps research work and want to know understand whether it helps everyday software engineering tasks. We built out 9 tasks to measure this and compared using only a Coding Agent (Opus 4.6) (baseline) vs Coding Agent + Paper Lantern access.
(Blog post with full breakdown: https://www.paperlantern.ai/blog/coding-agent-benchmarks)
Some interesting results : 1. we asked the agent to write tests that maximize mutation score (fraction of injected bugs caught). The baseline caught 63% of injected bugs. Baseline + Paper Lantern found mutation-aware prompting from recent research (MuTAP, Aug 2023; MUTGEN, Jun 2025), which suggested enumerating every possible mutation via AST analysis and then writing tests to target each one. This caught 87%.
2. extracting legal clauses from 50 contracts. The baseline sent the full document to the LLM and correctly extracted 44% of clauses. Baseline + Paper Lantern found two papers from March 2026 (BEAVER for section-level relevance scoring, PAVE for post-extraction validation). Accuracy jumped to 76%.
Five of nine tasks improved by 30-80%. The difference was technique selection. 10 of 15 most-cited papers across all experiments were published in 2025 or later.
Everything is open source : https://github.com/paper-lantern-ai/paper-lantern-challenges
Each experiment has its own README with detailed results and an approach.md showing exactly what Paper Lantern surfaced and how the agent used it.
Quick setup: `npx paperlantern@latest`
Coding agents miss research knowledge; this surfaces 2M+ papers with benchmarks.
Research synthesis for code is interesting, but needs live product beyond email signup.
Filters out SEO bait and vendor whitepapers to feed agents only top-tier venue papers.
Research-backed prompt scoring that runs locally in under 1ms with zero LLM calls.
Useful Claude Code skills wrapper but five minutes per paper claim is marketing hyperbole.
Naur's 1985 theory applied to AI agents, but it's just a prompt template.