Finance●Mid
Maxcred – app to maximise your credit card rewards
Free alternative to Max Rewards, but the 16-card catalog is too small to be useful yet.
Solve My ProblemCozy
theoo21
201mo ago
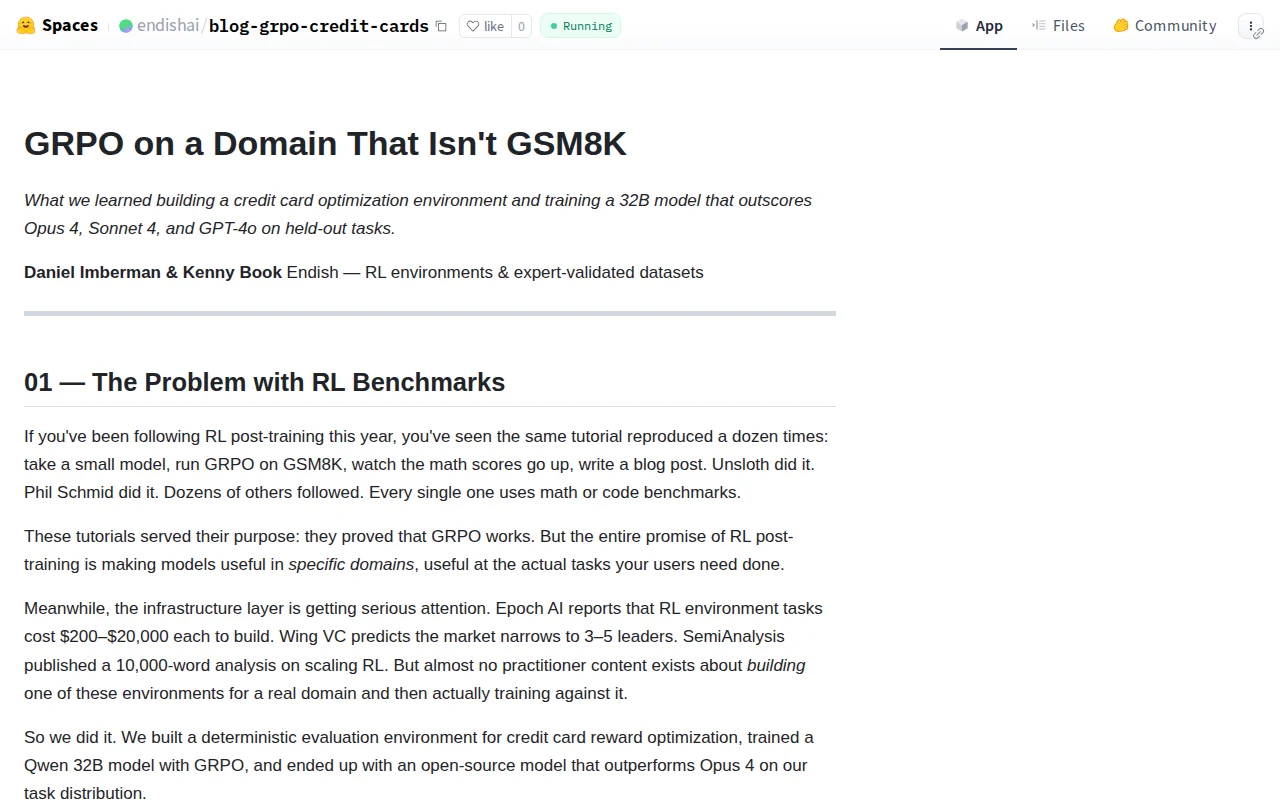
GRPO-trained Qwen 32B beats Opus 4 on credit card tasks — specific domain win.
ML engineers, RL researchers, fintech developers
Outlines · RLHF libraries · Domain-specific fine-tuning pipelines
Free alternative to Max Rewards, but the 16-card catalog is too small to be useful yet.
Useful directory, but Sweepbase already does the heavy lifting for comparisons.
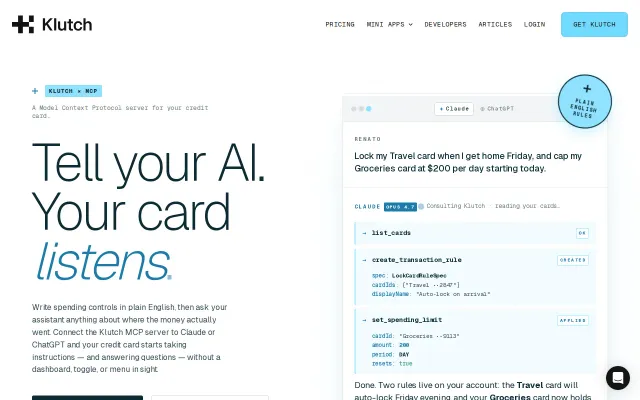
MCP server for credit cards is clever but only works if you have a Klutch card.
Manual credit tracking app competing against MaxRewards and CardPointers.
Local LLM statement parser with chat, but Monarch Money and YNAB already handle this.
Idle game mechanics actually teach overfitting and compute tradeoffs correctly.