AI/ML●●●Banger
Building a Stateful AI Agent
Event spine architecture makes context a cache, not storage — genuinely novel approach.
Big BrainWizardry
suryaankata
205d ago
High-recall search API for event monitoring that beats Exa on benchmarks.
Backend developers building compliance or risk monitoring pipelines
Exa · NewsCatcher · Google Programmable Search
Artem and Maksym from NewsCatcher here.
Some of you know us as we started six years ago as two freshly graduated economics students who decided to build the best news API product.
We started NewsCatcher thinking the market for news APIs was so big that we could build a self-serve platform and get millions of $29 users.
Obviously, it was a wrong assumption. We pivoted to serve enterprises and had success with it.
But we are hackers at heart, and we want to serve hackers.
We haven't used our Launch HN yet, so consider this our smoke test.
We're looking for feedback and power users rather than revenue. So, happy to provide enough credits for any HN user who finds CatchAll useful.
CatchAll is built for one thing: retrieving every matching event from the web. The use cases that fit it are ones where missing events have real consequences — funding and M&A monitoring, regulatory and compliance feeds (FDA approvals, SEC filings, policy changes), cybersecurity incident tracking, supply chain signals.
If your pipeline consumes structured records and the answer to your query is "find all of them," that's where it works. It's not the right tool for small, bounded queries that return 5 high-precision results.
The 15-minute job time is a direct consequence of the pipeline depth: analyze, fetch, cluster, validate, extract, deduplicate. You're not getting a ranked list of links; you're getting a verified record set.
Our latest benchmark run: https://newscatcherapi.com/blog-posts/web-search-api-benchma...
Event spine architecture makes context a cache, not storage — genuinely novel approach.
Vital for Iran researchers, but technically just a searchable directory with no novel tech.
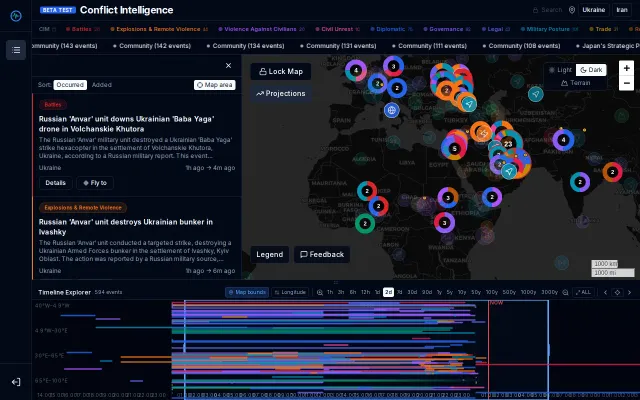
Automated storytelling mode flies you through events with voice-over narration.
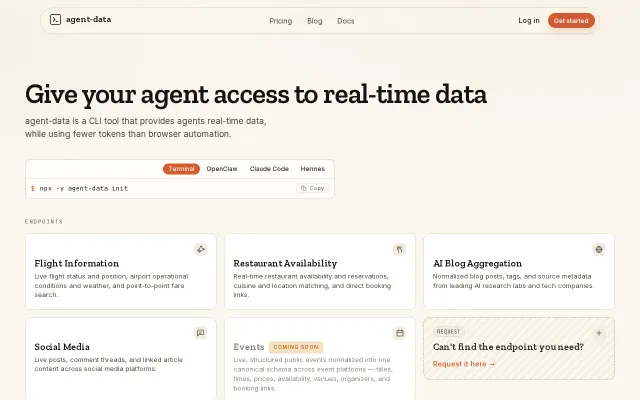
Generates event catalogs from code in two commands, replacing manual schema docs.
Blog post positioning a SaaS tool, not a product or project worthy of Show HN.
Structured flight and restaurant APIs beat brittle browser automation for agents.