AI/ML●●Solid
An agent that tunes its own cache
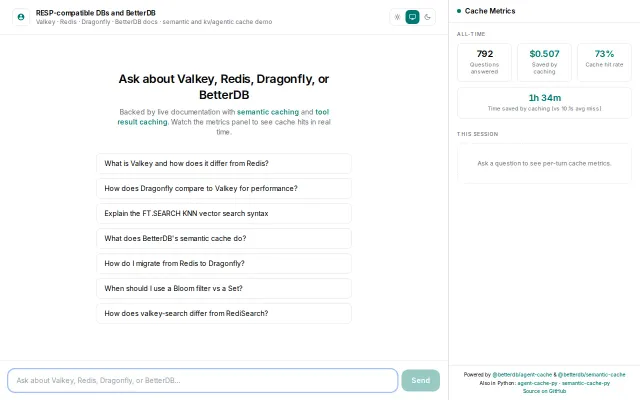
Two-tier caching saves real money, shown live on the dashboard.
Ship ItBig Brain
kaliades
701mo ago
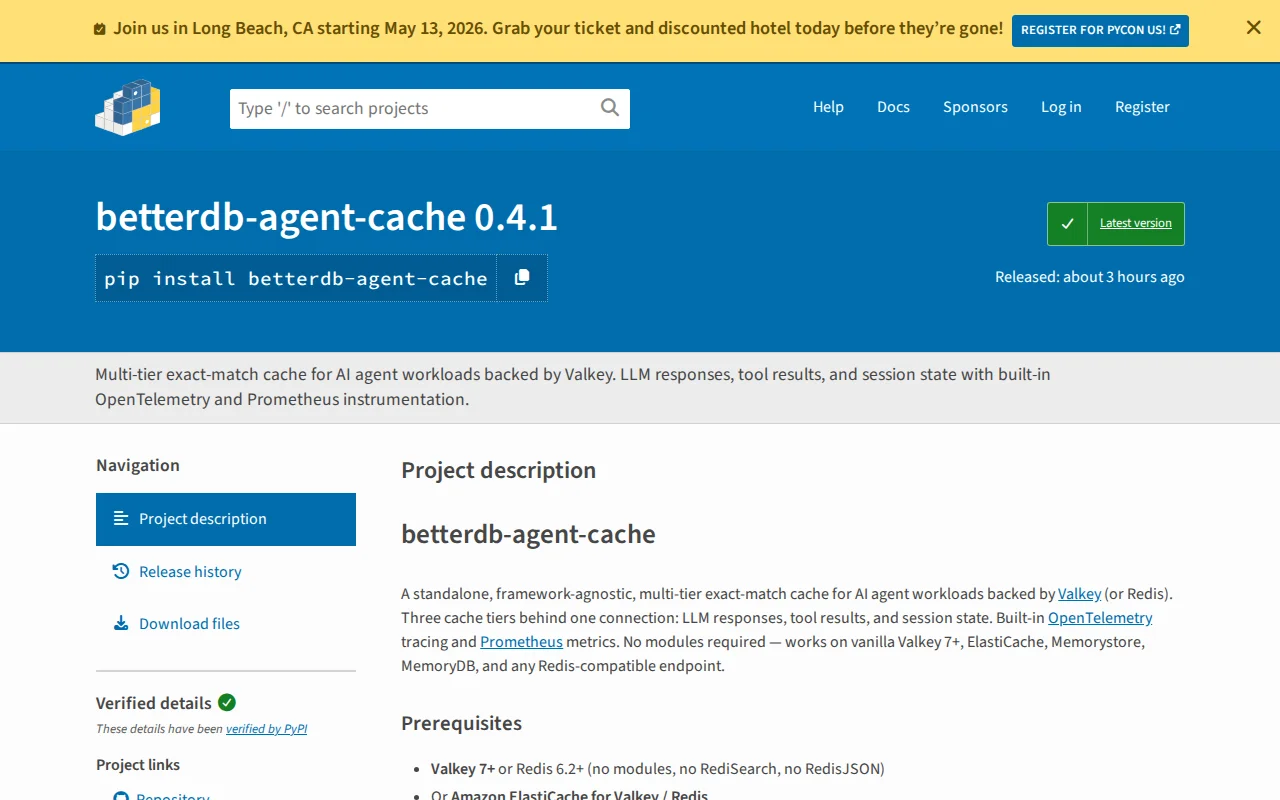
Multi-tier cache for AI agents with built-in OpenTelemetry and Prometheus metrics.
AI Engineers, Backend Developers
LiteLLM · LangChain · Redis
Two-tier caching saves real money, shown live on the dashboard.
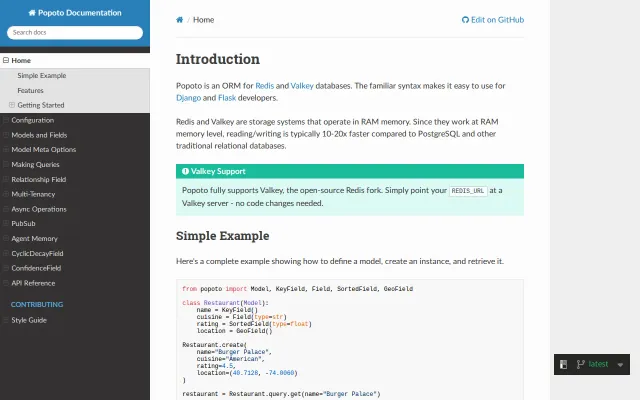
Django-style Redis ORM with timely Valkey support and AI agent memory primitives.
One-line init with monkey-patching means zero changes to existing agent code.
Yet another LLM orchestration layer over LiteLLM + Pydantic when DSPy and LangChain dominate.
Another agent orchestration layer competing with LangGraph, CrewAI, and AutoGen.
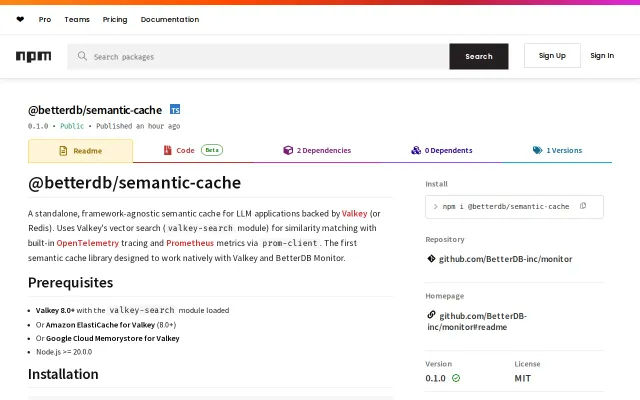
First semantic cache handling Valkey Search 1.2 divergences without silent breaks.