AI/ML●●Solid
Mamba SSM in Rust – training and inference with custom CUDA kernels
Custom CUDA kernels for SSM recurrence with zero framework dependencies.
WizardryNiche Gem
silvermpx
103mo ago
Custom CPU kernels for sparse training when everyone else chases GPU.
ML researchers and PyTorch developers working with sparse models or CPU-only environments
PyTorch Sparse · DeepSpeed · Fairscale
Custom CUDA kernels for SSM recurrence with zero framework dependencies.
Per-agent PPO runtime with tensor-first simulation state is genuinely clever architecture.
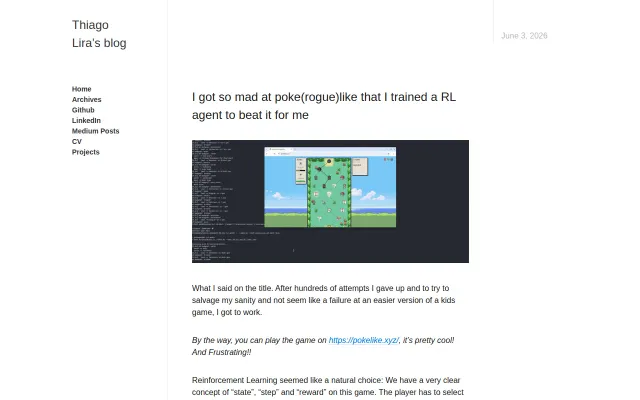
178K neural net beats Pokémon roguelike with clever 1386-dim state encoding.
Vectorized multi-agent RL combat sim with deterministic checkpointing and telemetry logging.
Two MacBooks syncing gradients over Thunderbolt — slower than single-GPU but it works.
Autonomous kernel optimizer that won MLSys contest with 34.93x speedup.