Data●●Solid
Streambed – Stream Postgres to Iceberg on S3, Supports Postgres Wire
Query Iceberg tables directly via psql without spinning up Trino or Spark clusters.
Solve My ProblemBig Brain
vira28
1294014d ago
Ephemeral ClickHouse on demand beats Kafka pipelines — but early access limits confidence.
Developers building AI agents that need real-time database access
Fivetran · Airbyte · Materialize
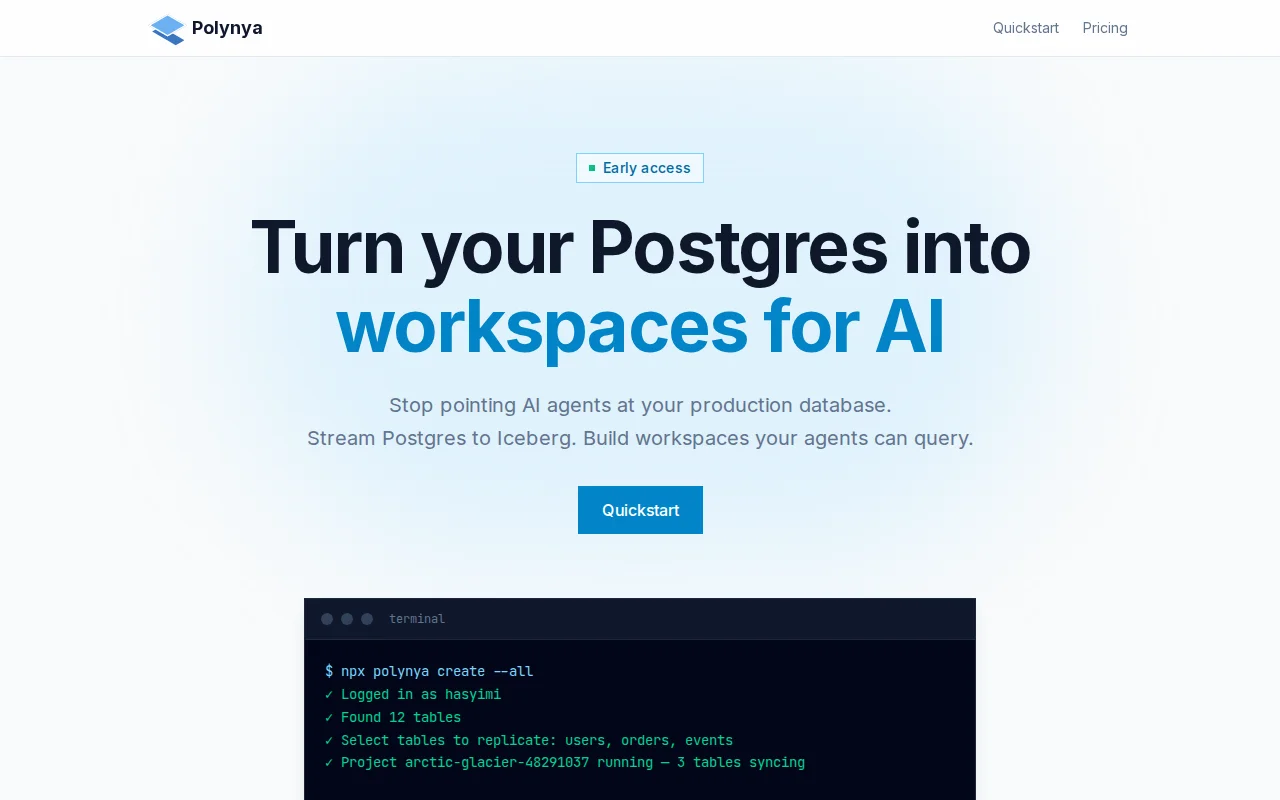
The solution: Polynya replicates your data into Iceberg, and gives your agent an ephemeral ClickHouse instance on demand. Polynya also provides persistent workspaces — collections of views that survive across sessions. So from your agent's point of view, it's a 24/7 data warehouse.
At its core, Polynya is a data platform for streaming real-time data from Postgres to Iceberg. But instead of spending hours setting up costly and complex pipelines involving Kafka, Debezium, Flink, etc., Polynya lets you do this with just one command:
npx polynya create
It's currently free on early access, so do try it out and give me any feedback! Currently there is no web dashboard yet (coming soon), you interact with it 100% through CLI.
P.S. Polynya is built on top of pg2iceberg, the open source Postgres to Iceberg replication tool I've been building for the past few weeks: https://pg2iceberg.dev/
Query Iceberg tables directly via psql without spinning up Trino or Spark clusters.
BM25 search directly on S3 Parquet files without ingesting data into Elasticsearch.
Apache Iceberg for observability data cuts costs versus Datadog and Honeycomb pricing.
Postgres RLS plus S3 bucket policies in one CLI for DuckLake auth.
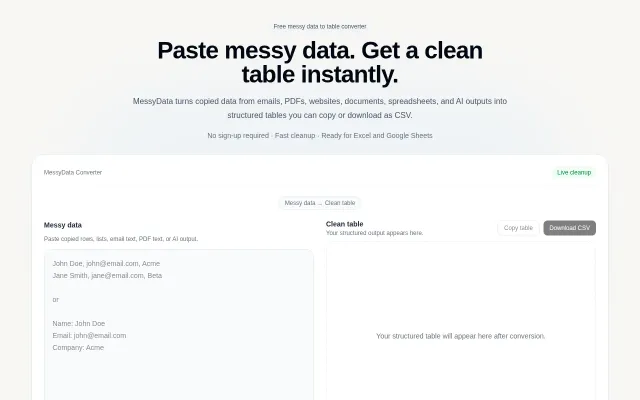
Useful for quick cleanup, but JinaAI and LLMs already handle this natively.
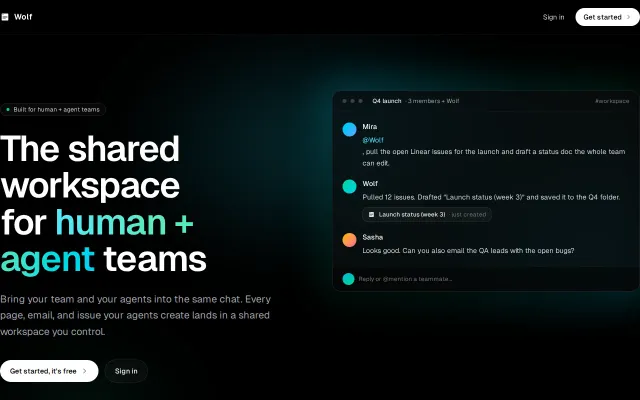
Persistent artifacts and permissions system beat Slack-plus-ChatGPT workflows.