AI/ML●Mid
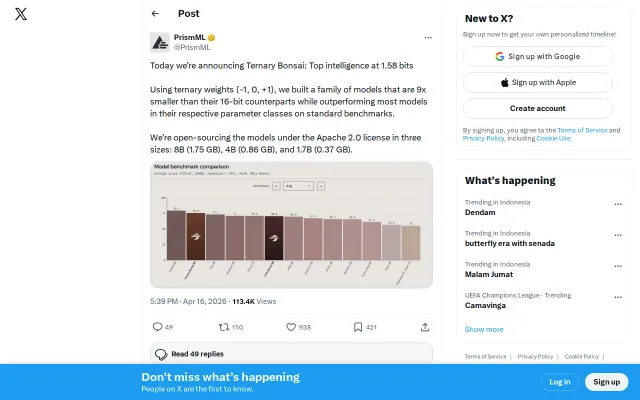
Ternary Bonsai, delivering top intelligence at 1.58 bits
Ternary weight quantization claims are bold, but where's the code or paper?
Bold Bet
bansaltushar92
302mo ago

Autonomous agent wrote custom Metal kernels boosting decode speed 42% over upstream llama.cpp.
Mac developers, local LLM enthusiasts, ML engineers
llama.cpp · MLX · Ollama
Ternary weight quantization claims are bold, but where's the code or paper?
Native ternary training beats post-training quantization for memory efficiency.
Comprehensive inference survey from CUDA to Kubernetes, but it's a book not a tool.
Cross-chip agent knowledge sharing beats CoreML by 6× on Apple Silicon.
11 model families ported to Core AI with verified on-device benchmarks on iPhone 17 Pro.
Ternary quantization and layer streaming for 140B models on Mac Mini, but claims lack real-world validation.