Education●Mid
Browsable index of every lecture and talk from the CMU Database Group
Curated YouTube index when the channel's own playlists already exist.
Niche Gem
tamnd
102mo ago
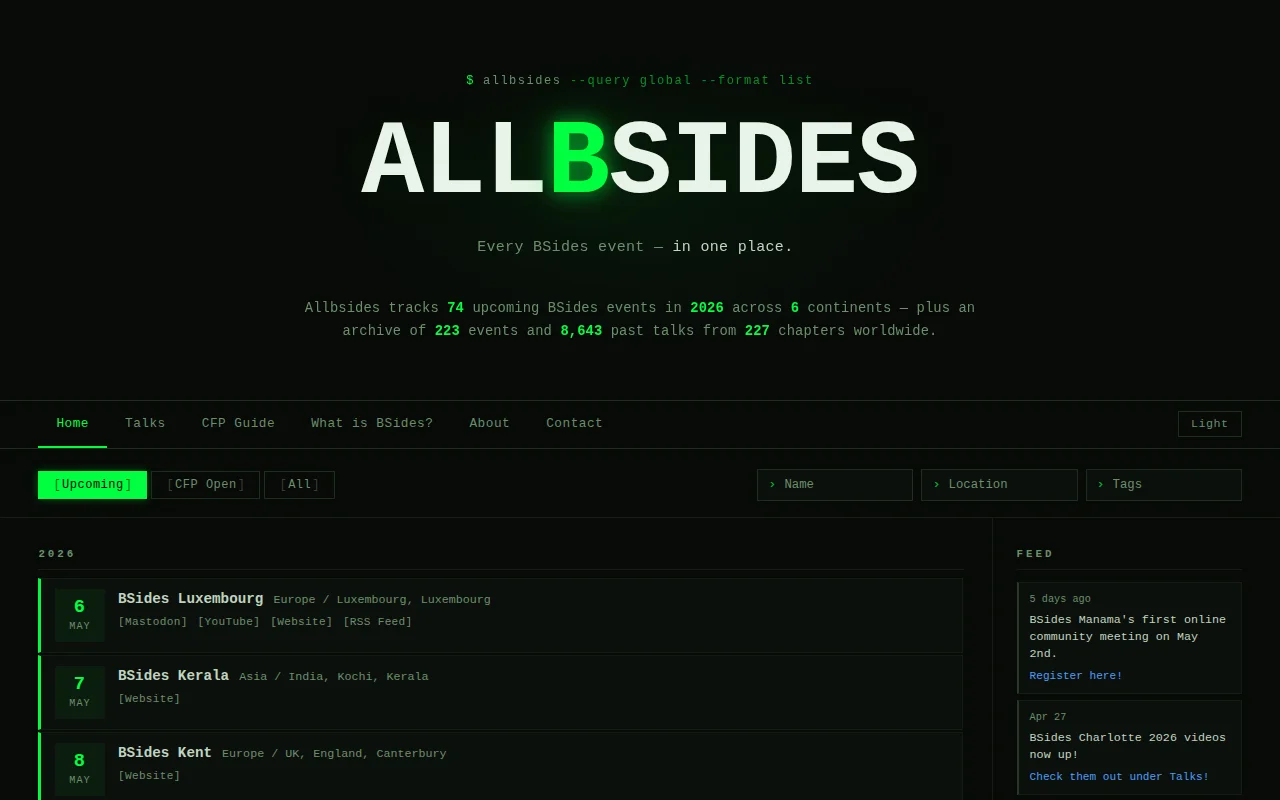
Massive archive of 8k talks, but LLM tagging feels like overkill for a directory.
Security researchers, conference attendees
YouTube · InfoQ · Archive.org
I'm Roland, and for the past few weeks, I've been building AllBSides — a directory of every BSides conference talk uploaded to YouTube. As of today, 8,643 talks from 5,927 speakers across 227 chapters in 68 countries. Combined runtime is 280 days. The transcripts come to about 60 million words.
The archive came together in stages:
1. Manually map every BSides chapter's YouTube channel 2. Pull every video and transcript from Supabase 3. Run each transcript through Haiku for tag extraction (tools, topics, difficulty, team, talk style, research method, and much more) 4. Run results through Sonnet for categorization and dedup 5. Final pass goes through Opus for verification 6. Do a manual verification - at one time, the pipeline showed over 16k AI suggestions for manual verification. Today, most are resolved.
Total LLM cost so far: about €200. The whole pipeline is rebuildable from scratch.
Each talk gets its own page with embedded video, full transcript, speakers, tags, and "related talks." Each tool/framework/protocol/standard mentioned across the corpus gets its own page (3,968 distinct technologies tracked).
Some interesting facts I gathered while building it:
-(A) The site is currently 94% bot traffic. Of that, about 80,000 hits/month are AI training crawlers (ClaudeBot, GPTBot, meta-externalagent). Within 7 days of the talks archive going live, all major AI labs had ingested the entire corpus. The discovery cascade was startling to watch in real time.
-(B) The taxonomy work was the hardest part. Distinguishing "tools" from "frameworks" from "protocols" from "concepts" sounds easy until you have 5,000 ambiguous extracted entities. The 3-tier LLM pipeline helped a lot — Haiku alone was too noisy, Opus alone was too expensive.
-(C) Top tools mentioned: Wireshark (343), PowerShell (342), Metasploit (332), Burp Suite (322), GitHub (296), VirusTotal (273), Docker (253), Splunk (251), Nmap (247), MITRE ATT&CK (237). The list reflects what BSides talks actually discuss, not what vendors curate.
-(D) May is the peak BSides month — 29 events, 17% of all events with dates.
-(E) The top 1% of talks (86 videos by view count) account for 51% of all viewership. The other 99% are deeply niche, often the only video record of a specific technique.
The stack is intentionally lean: Go, SQLite, vanilla JavaScript, BunnyCDN. Static rendering at build time. No frameworks, no client-side state. The site costs about €50/month to run.
The data behind this post and much more can be found in the site footer, under the link "stats".
Happy to answer questions about the data pipeline, the taxonomy decisions, or what the AI crawler patterns looked like as the archive went live. Feedback on what to build next is genuinely welcome — I'm a solo dev figuring this out as I go.
— Roland (parkado)
Curated YouTube index when the channel's own playlists already exist.
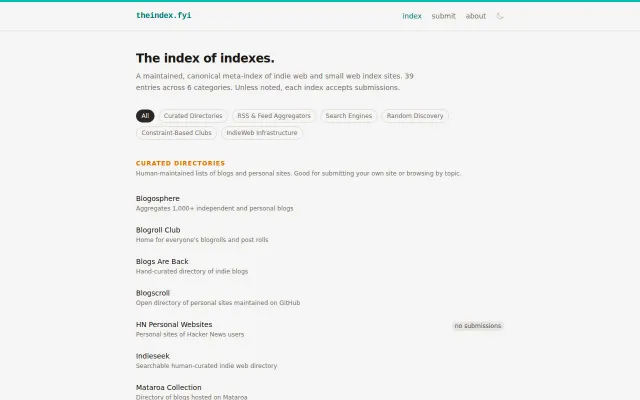
Finally, a single place to find all those scattered indie web directories.
ChatGPT prompt indexer, but unclear what problem this solves over native search.
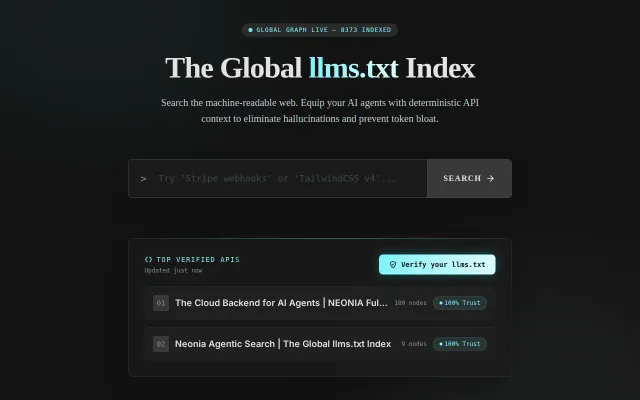
Searchable directory for llms.txt files when general search engines could index these.
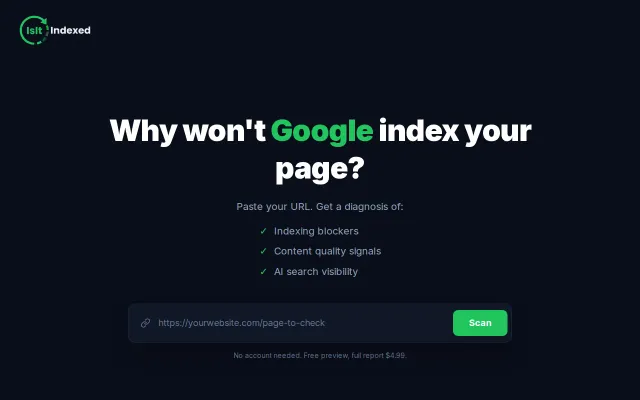
Checks if GPTBot and ClaudeBot are blocked before Google even sees your page.
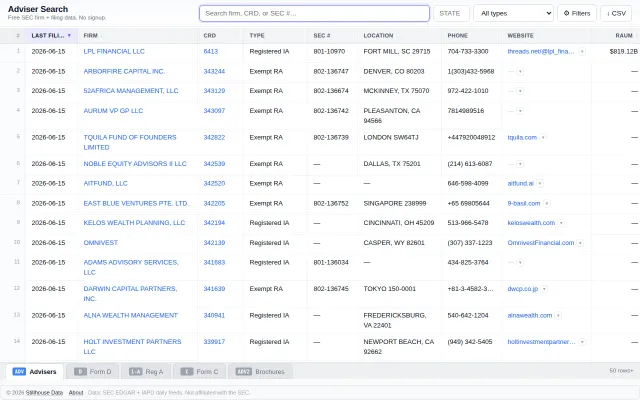
Clean SEC data UI when EDGAR and IAPD already exist for free.