Developer Tools●●●Banger
Cheddar-bench – unsupervised benchmark for coding agents
Unsupervised bug benchmark using agents as both attackers and defenders—novel scoring methodology.
Big BrainWizardryShip It
przadka
904mo ago
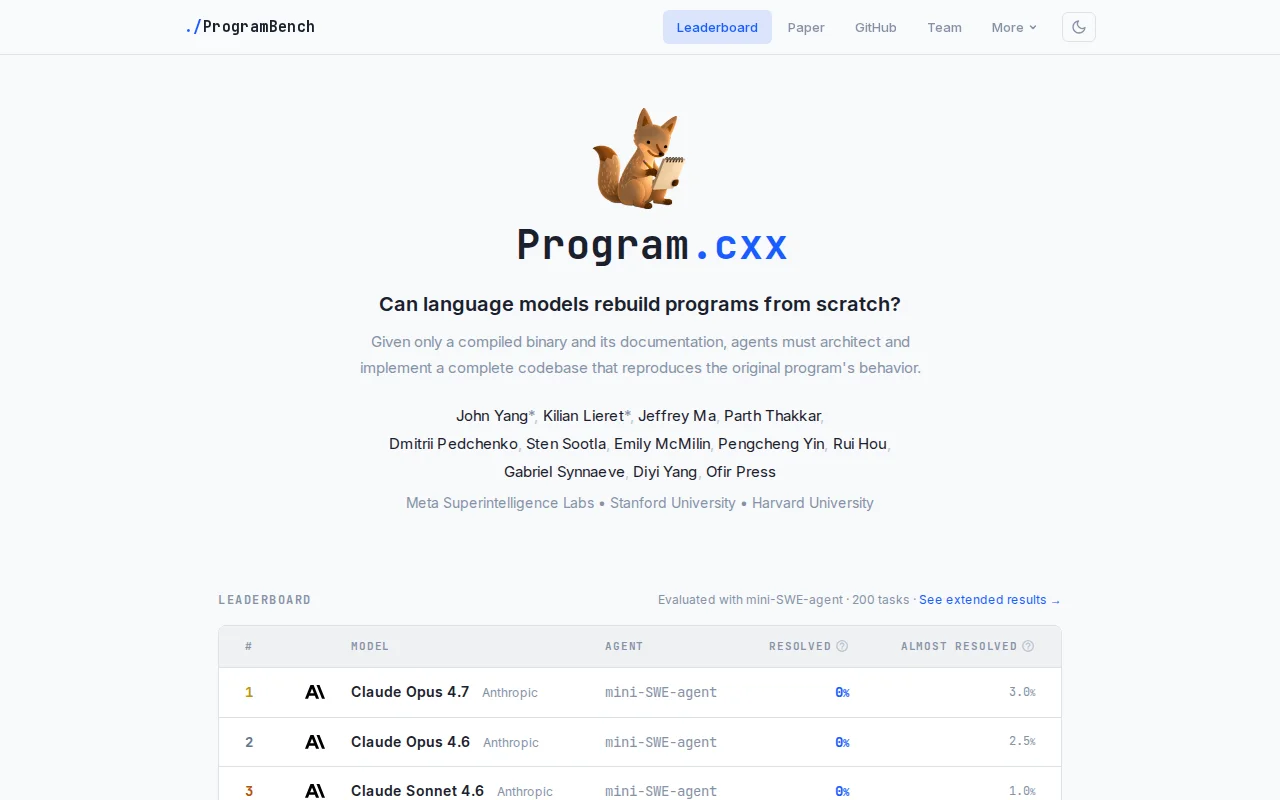
Agents fail completely at rebuilding binaries from scratch without source code.
AI researchers, LLM developers, Benchmark enthusiasts
SWE-bench · HumanEval · LiveCodeBench
Unsupervised bug benchmark using agents as both attackers and defenders—novel scoring methodology.
LLM judge on outgoing requests achieves 0% cheat rate while preserving 58% fair-solve ceiling.
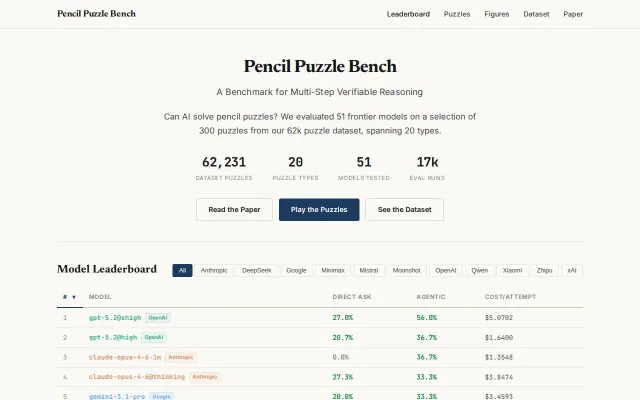
62k puzzle benchmark reveals reasoning depth, cost variance, and stark US vs China model gaps.
97% on SWE-bench Verified with full artifact transparency, not just a score claim.
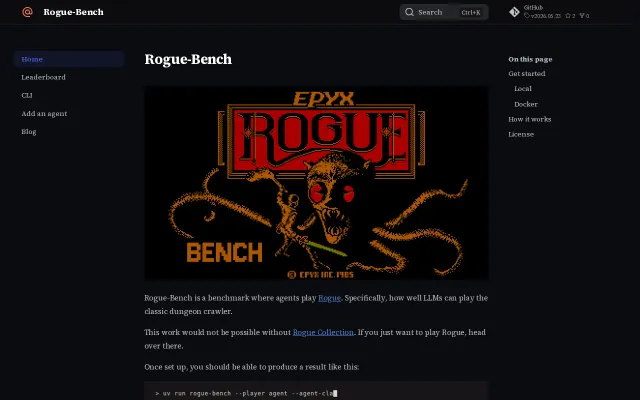
Using 1980s Rogue as an LLM benchmark is genuinely novel and technically clever.
Tests agents on 700 policy docs and noisy voice calls where AgentBench stops.