AI/ML●●Solid
Nexa-Gauge – LLM eval framework, now with self-hosted model support
Cache-aware LLM eval with self-hosted model support beats Ragas on flexibility.
Solve My ProblemSlick
Sardhendu
201mo ago
An graph-eval framework for LLM's
Cache-aware execution cuts eval costs while tracking grounding and relevance metrics.
ML engineers, LLM application developers, QA teams
Ragas · LangSmith · Arize Phoenix
Cache-aware LLM eval with self-hosted model support beats Ragas on flexibility.
Semantic caching for LLM APIs exists (Anthropic prompt caching, Langchain, Miniplex, vLLM); gateway routing is table stakes.
Graph RAG without Neo4j — pure vector search beats HippoRAG on multi-hop benchmarks.
LLM gateway with Redis + Qdrant caching, but LiteLLM does this.
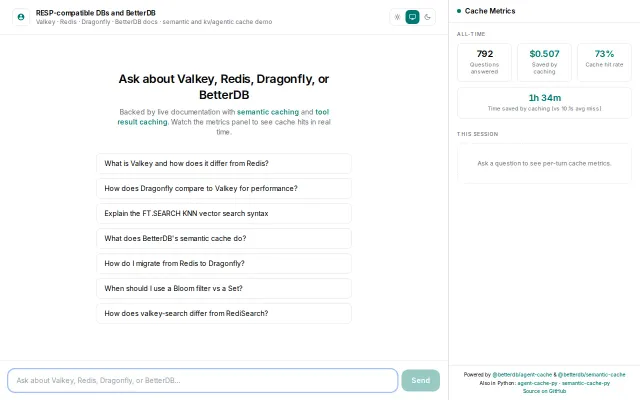
Two-tier caching saves real money, shown live on the dashboard.
LLM cost optimizer, but Anthropic's batch API and local quantization solve this cheaper.