Education●●Solid
Inference Engineering
Comprehensive inference survey from CUDA to Kubernetes, but it's a book not a tool.
Solve My ProblemNiche Gem
philipkiely
203mo ago
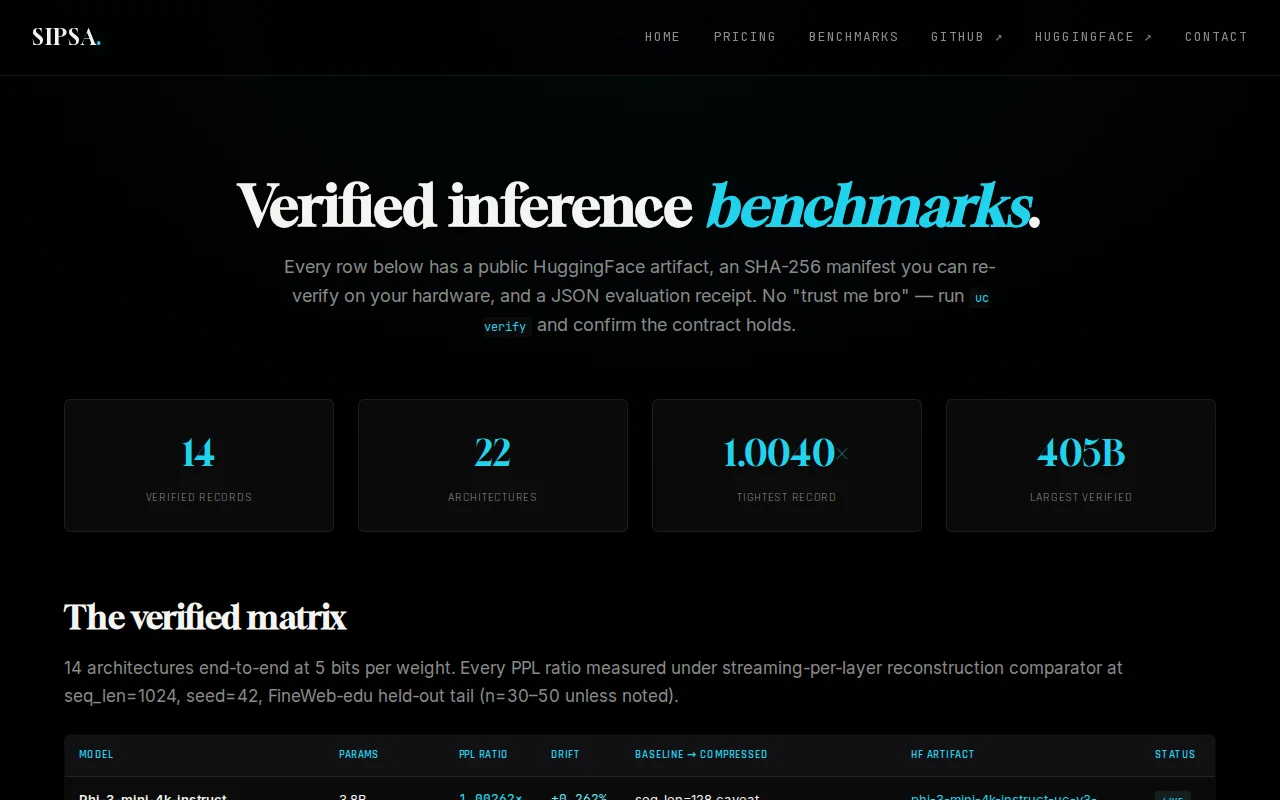
SHA-256 verifiable manifests prove lossless compression mathematically, not just statistically.
ML engineers and researchers deploying large language models on limited hardware
bitsandbytes · AWQ · GGUF
Comprehensive inference survey from CUDA to Kubernetes, but it's a book not a tool.
Runs 405B model compression on a single 32GB GPU when others need enterprise clusters.
Standalone KV cache compression script implementing TurboQuant with 1.55x ratio.
3.59ms for 100 LoRA adapters with zero HBM writes—genuine GPU wizardry.
336× faster tree model inference; compiles sklearn/XGBoost to C99, serves like Ollama.
INT4 inference engine beats llama.cpp on VRAM, but competing against established tools.