Other○Pass
Potatoverse, home for your vibecoded apps
Extremely minimal documentation; unclear what "vibecoded" apps are or how this differs from existing platforms.
born-jre
623mo ago
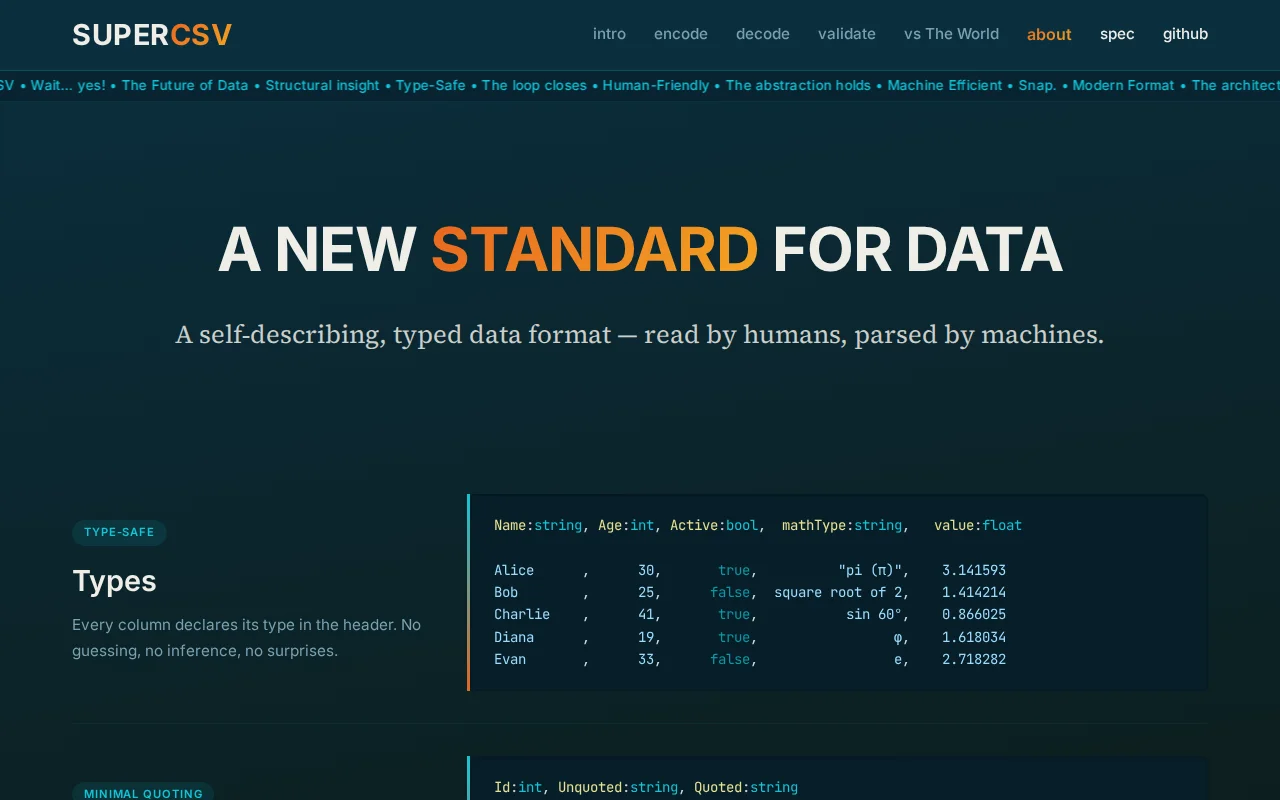
Typed CSV format competing against Parquet, Avro, and JSON Schema.
Data engineers and backend developers dealing with CSV parsing issues
Parquet · Avro · JSON Schema
SuperCSV is a CSV-like data format with explicitly defined types and self-describing files.
SuperCSV v1.0 includes a formal specification, a reference implementation in Go (validation, encoding, decoding), and a public test suite.
Extremely minimal documentation; unclear what "vibecoded" apps are or how this differs from existing platforms.
Self-describing archive blocks with mandatory CRC32 and no fallback tricks.
DNA-encoded ULID makes knowledge cards globally unique, sortable, and decodable offline forever.
Ambitious self-describing data format, but 'free Lovable' claim oversells it.
Compiler-level validation turns Qwen's 6.75% structured output success rate into 100%.
Impressive engineering choices — bytecode/AST generation for ~64% faster dumps and explicit Pyodide/WASM support show someone wrestled real performance and portability problems. It bundles one API across JSON, YAML, TOML, MsgPack/CBOR/BSON and adds native numpy/pandas handling plus basic validators and schema output. Still, it lives in a crowded Python serialization space (pickle, orjson, pydantic/serde alternatives), so adoption will hinge on ecosystem compatibility and convincing users to switch.