AI/ML●●●Banger
LLM Sycophancy Benchmark: Opposite-Narrator Contradictions
Opposite-narrator test catches models agreeing with both sides of same dispute.
Big BrainDark Horse
zone411
303mo ago
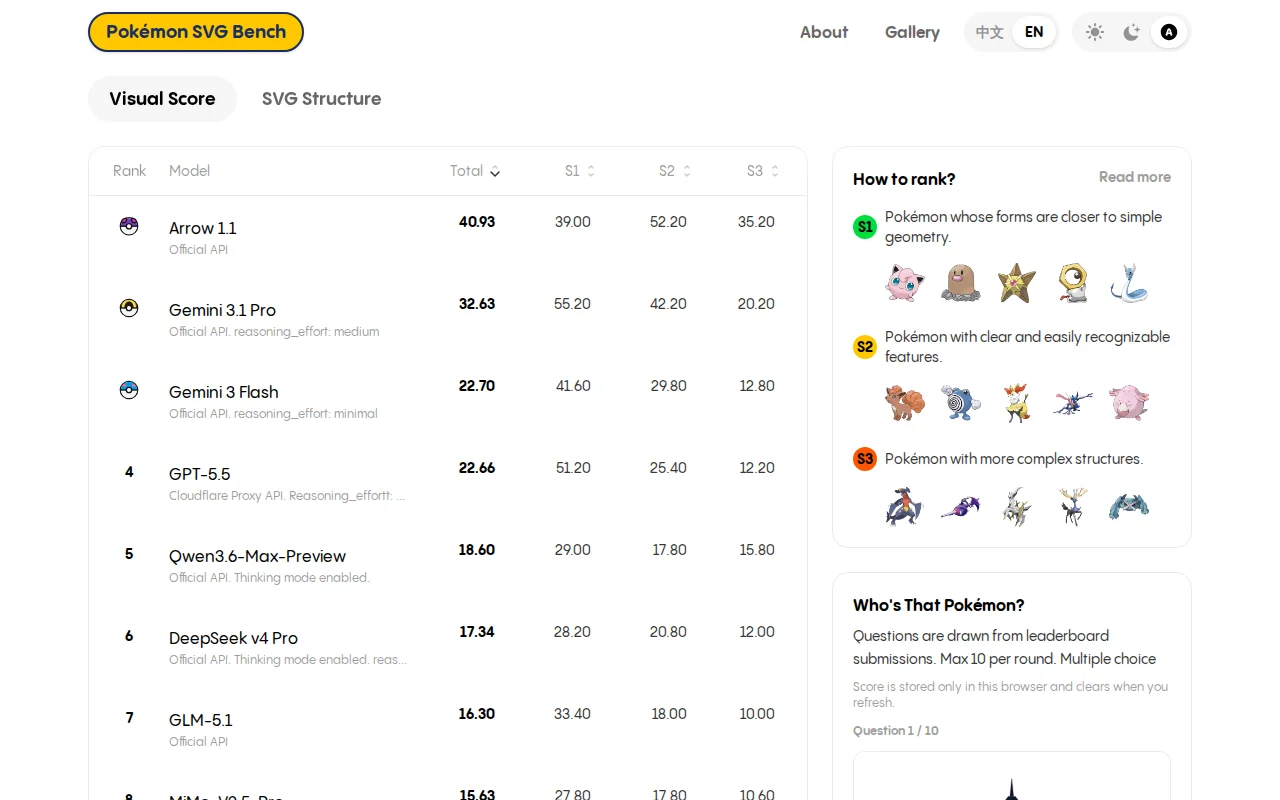
Finally, a benchmark that uses Pokémon to test if models understand complex geometry.
AI researchers and developers interested in multimodal model capabilities
SVG-Bench · GenAI Benchmarks
Opposite-narrator test catches models agreeing with both sides of same dispute.
Side-swapped debate matchups expose model weaknesses standard benchmarks miss.
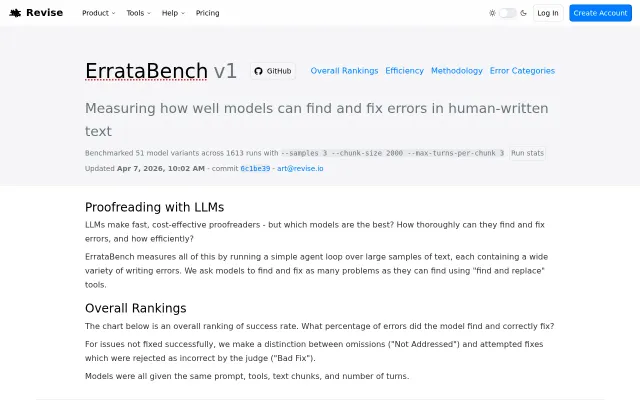
51 models, 1613 runs, $558 spent — finally proofreading benchmarks with real numbers.
Home rig for attribute-weighted benchmarking lacks the polish of established eval frameworks.
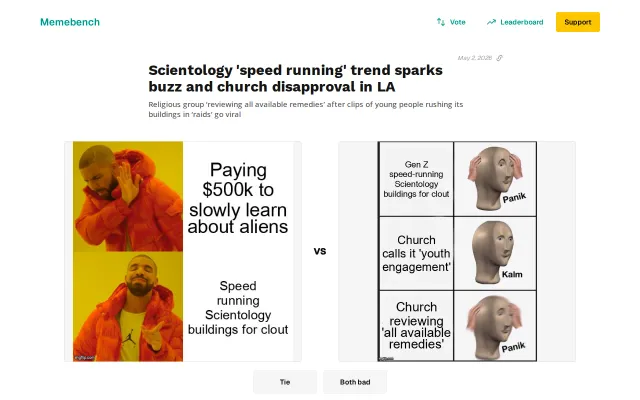
Automated meme generation is fun, but lacks depth beyond the novelty.
Postman for local LLMs with LLM-as-Judge and Elo ratings built in.