Productivity●●Solid
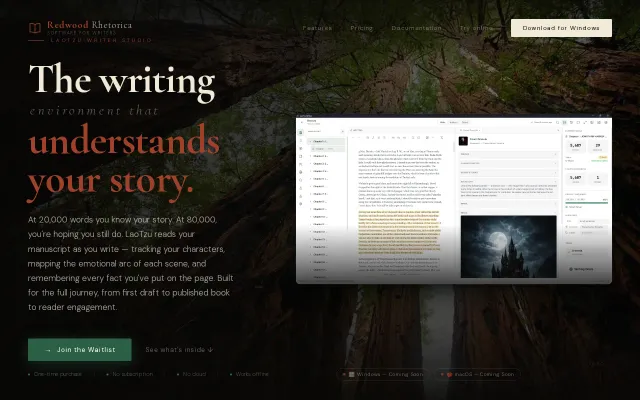
LaoTzu Writer Studio
Story Compass visualizes narrative structure better than Scrivener's corkboard ever could.
CozyNiche Gem
homeonthemtn
831mo ago
Continuity checker for novels, but Scrivener and ProWritingAid already cover this ground.
Fiction writers and novelists
Scrivener · ProWritingAid · Atticus
We originally tried a named entity recognition-based approach with the goal of tracking entities, attributes, and relationships across the manuscript. We benchmarked on 96 novels from Project Gutenberg with various inconsistencies injected into each one, then ran the "The Guardian" layer across them to ferret them out. Unfortunately this presented 2,500 false positives across 96 novels, so ~26 false positives a novel. It's not technically bad but it's enough to become an unreliable nuisance of a feature
For our next approach, we instead opted to build our own model, which we call "Confucius". This is a purpose-built narrative world model that sits underneath the entire analysis layer.
It consists of five structures which I'm just lazily copying and pasting from our docs here: PropertyGraph — entities as nodes, relationships as weighted edges, co-occurrence counts CausalDAG — setup/payoff chains, unresolved narrative threads IntervalTree — precise word-position intervals for every entity (where is each character in the manuscript at every point) FenwickTree — entity density over word position, O(log n) range queries Trie — fuzzy entity lookup, name variants, partial matches
Confucius is passive in that it only knows what you tell it via an event emission system. We then slot in an LLM for the extraction layer. We tested three approaches for said LLM
1. NER Only
2. Local GGUF Model only
3. Anthropic Haiku Only
NER, in any combination, made things worse, it was low detection and generated the same high number of false positives. GGUF resulted in 100% detection, with zero false positives, and likewise for Anthropic
So based on this, we opted to ship with 3 tiers - heuristic only (no AI required, but basic surface metrics), local GGUC (Qwen3, ~500mb one-time download which enables full Guardian features), or a managed API subscription (Haiku on our key)
We're certainly proud of the result, but unto itself its been a fascinating journey as we surface additional features with each model refinement (e.g. "voice fingerprint" is our newest - essentially the consistency of the characters voice over the span of the book)
We've got a kickstarter going to help fund refinements and model expenses[1], and a roadmap for additional apps down the line which we'll have on the main site[2]. We'd love for folks to try out the app so we can get some real user feedback for UI/UX refinements so please do check out the demo, or just ping us on the side
1. https://www.kickstarter.com/projects/laotzustudio/laotzu-wri...
Story Compass visualizes narrative structure better than Scrivener's corkboard ever could.
Interactive fiction tooling with portable format—but audience is writers, not developers.
Turns audiobooks into graphic novels with character consistency across chapters.
Typing-based interactive fiction platform selling narrative adventures like game DLC.
Forty-line bash script swapping Claude signoffs for fictional characters.
Fun LLM simulation wrapper, but novelty wears off after trying five inboxes.