AI/ML●●Solid

WebGPU LLM inference comprehensive benchmark
Sequential-dispatch methodology corrects 20x overestimation in prior WebGPU benchmarks.
Big BrainNiche Gem
yu3zhou4
222mo ago
A suite to benchmark CPU/GPU Python performance in training ML models and running local LLMs
One-command benchmark suite comparing Ollama and XGBoost performance with a shared Streamlit dashboard.
Data scientists and ML engineers comparing local hardware for model training
Phoronix Test Suite · MLPerf · UserBenchmark
Sequential-dispatch methodology corrects 20x overestimation in prior WebGPU benchmarks.
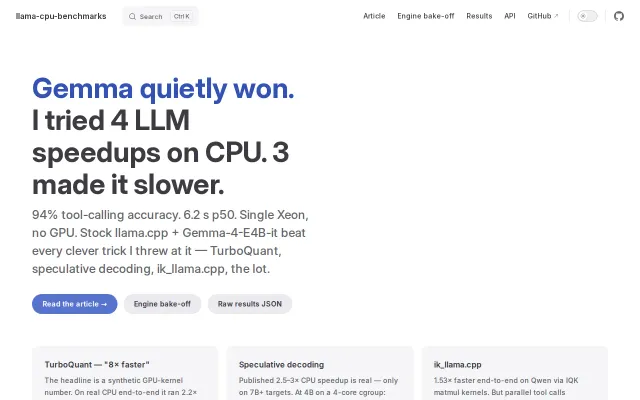
Proves speculative decoding slows down 4B models on 4-core CPUs despite marketing claims.
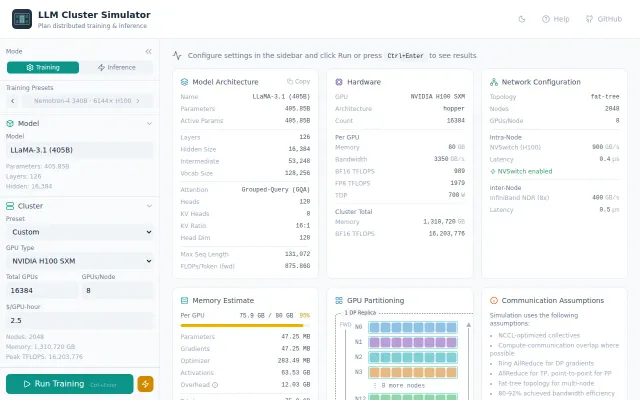
Estimates LLM training MFU, memory, timeline across 70 models and parallelism strategies—genuinely useful before GPUs commit.
Explicit kernel control over TVM-style black boxes, but benchmarks show mixed wins vs Transformers.js.
Blog post masquerading as a product; no code, no reproducible implementation.
28% faster Vulkan-to-CUDA on Qwen, but llm.c and llama.cpp already own inference.