Developer Tools●●●Banger
Callmux – MCP multiplexer that cuts tool call context pollution by ~19x
19x context pollution reduction via batching — solves a problem nobody's talking about yet.
Big BrainWizardry
edimuj
201mo ago
Caches bloated MCP responses and lets agents query with jq, saving real tokens.
Developers building AI agents with MCP servers
MCP Registry · LangChain tool caching
I've created a small wrapper for MCP servers that checks response sizes and forces agent to use filter on the response if response is large enough. In my tests (https://github.com/healqq/mcp-content-guard/blob/main/bench/...) it managed to save a decent amount of tokens while solving certain tasks (while added a bit of overhead in other tasks).
It works with both local and remote MCPs. Would be happy to hear your feedback and if that could be valuable for you!
19x context pollution reduction via batching — solves a problem nobody's talking about yet.
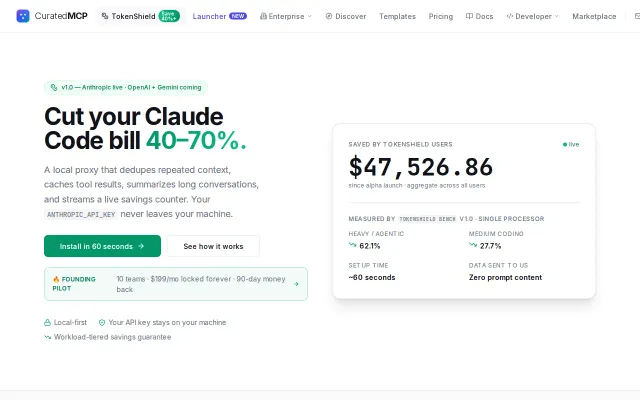
Six optimization layers slash Claude Code bills while keeping your API key local.
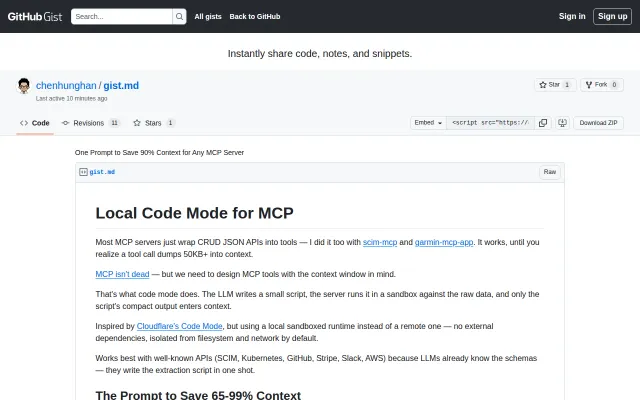
Sandboxed script execution saves context, but this is a gist not an implementation.
Maps tool explosion onto TypeScript discovery—elegant inversion that cuts context bloat by 99%.
Proxy-level LLM caching saves tokens during dev without instrumenting your code.
Reclaims wasted context tokens by auditing MCPs and skills before you type.