AI/ML●●●Banger
Glq LLM quantization using E8 lattice
E8 lattice codebooks beat GPTQ at 2-4 bpw with fused CUDA kernel skipping weight materialization.
WizardryBig Brain
acd
2013d ago
Replaces Tensor Cores with LUTs and bitwise ops for 3-bit edge inference.
ML researchers, embedded systems engineers, AI hardware architects
AWQ · GPTQ · GGUF
E8 lattice codebooks beat GPTQ at 2-4 bpw with fused CUDA kernel skipping weight materialization.
1-bit weights matching 8B model performance while running 132 tokens/sec on M4 Pro.
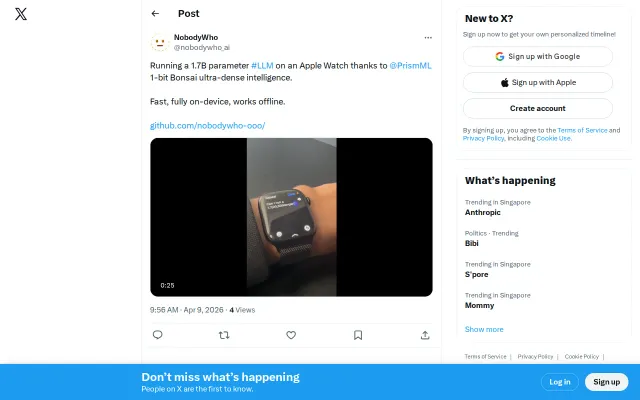
Runs a 1.7B LLM offline on Apple Watch using 1-bit quantization.
Proposal-first governance + hardware E-stop for AI controlling robots/drones—legitimately novel safety architecture.
Interesting diagnosis of AI statelessness, but six artifacts aren't directly accessible.
The repo outlines a concrete seven-layer protocol (SLP, World Model Interpreter, Agent/Persona/Knowledge layers, Metacognition, etc.) and even splits each piece into its own subrepo — that modular breakdown is the repo's strongest move. But this reads more like an ambitious manifesto and design spec than a working system: good docs and diagrams are present, yet there's little visible implementation, benchmarks, or reproducible evidence for the bold claims (like 40–70% token savings).