AI/ML●●Solid
Local-first fast CPU image to text for screenshots, PDFs, webpages
CPU-only OCR with clipboard round-trip when cloud APIs dominate the space.
CozySolve My Problem
mrkn1
191714d ago
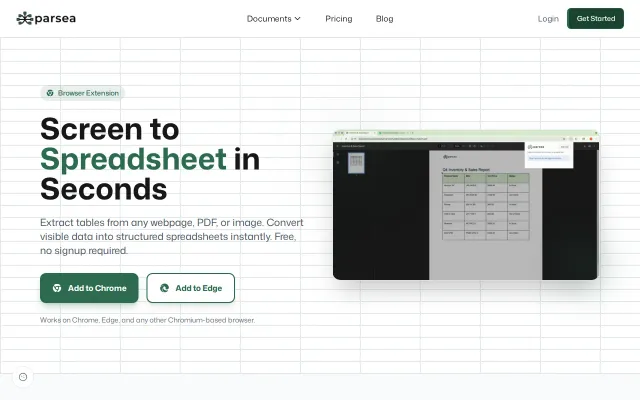
Snap any image, screenshot, or webpage into plaintext. No GPU. No cloud. One command.
CPU-only OCR with clipboard in/out beats Tesseract for modern screenshots.
Privacy-focused developers, offline workers
Tesseract · EasyOCR · NAPS2
CPU-only OCR with clipboard round-trip when cloud APIs dominate the space.
CPU-only VLM OCR beats Tesseract accuracy without sending data to the cloud.
CPU-only VLM OCR beats Tesseract on layout without needing CUDA or cloud APIs.
OCR-based extraction handles images and PDFs where standard DOM scrapers fail.
Yet another OCR API wrapper when JinaAI and Firecrawl already exist.
Go CLI with built-in OCR fallback when JinaAI and Firecrawl already handle this.