AI/ML○Pass
Krira Augment – Production-ready RAG in minutes
Waitlist for RAG platform launching in 2 months with no demo.
Bold Bet
kriralabs
103mo ago
Open-source web crawler in Rust
Competent Rust crawler when Scrapy and crawlee already solve this.
Developers building search indexes or content aggregators
Scrapy · crawlee · Heritrix
Waitlist for RAG platform launching in 2 months with no demo.
It skips headless Chromium entirely and implements an HTML/CSS-to-PDF pipeline in Rust, exposing a Python wheel and CLI that releases the GIL and uses Rayon for parallel batch renders. The deterministic bits — fixed-point base unit, --repro-record/--repro-check, SHA256 outputs and vendored assets — are a clear, practical play for audited VDP/transactional workflows; what's still unknown is CSS spec coverage and whether subtle print-layout quirks will require hand-holding.
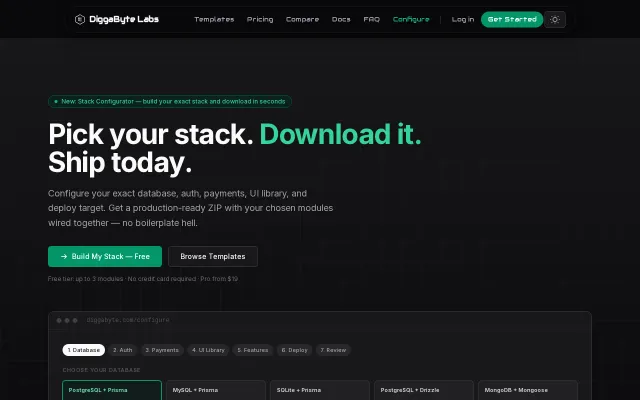
Drop-in SaaS scaffolding with Stripe, JWT, Prisma, and Docker pre-wired for $19/project.
Rust-powered crawler with CI/CD gates where Screaming Frog costs money.
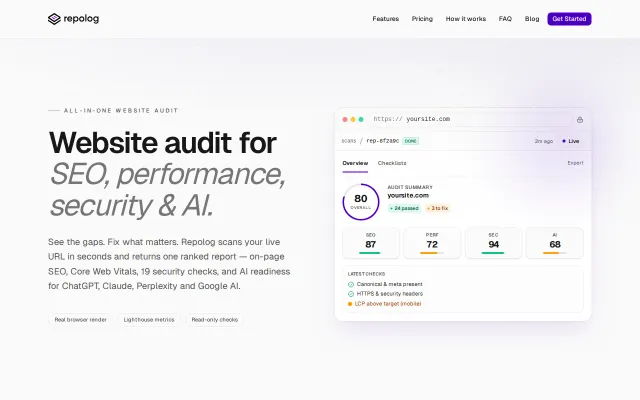
Yet another audit tool bundling Lighthouse, securityheaders.com, and basic robots.txt checks.
Wires the annoying auth plumbing — JWT with refresh/rotation, email activation, password reset, UUID user model, rate limiting and Swagger out of the box — so you can skip weeks of setup. The frontend is modern (TS + Vite, Tailwind, Radix) and includes route guards, but this is an incremental starter in a crowded space; I'd like to see deployment/CI examples or opinionated infra choices to make it truly turnkey.