Productivity●●Solid
macOS utility to record and playback mouse, keyboard events
Screenshot object recognition beats simple coordinate replaying.
CozySolve My Problem
harr01
401mo ago
Network Video Recorder and Playback
There are some smart engineering choices here — one FFmpeg process per camera that both serves HLS for live view and writes MP4 avoids multiple RTSP streams and makes detection on segments straightforward. Detection runs via ONNX YOLO on HLS segments with background‑subtraction to ignore static noise, plus tiered hot/warm/cold storage, calendar timeline playback, clip extraction and an LLM watchdog; it's feature‑dense and clearly built from real operating experience, though it competes with mature projects (Frigate/Shinobi) and will be judged on device compatibility and runtime reliability.
Self-hosters, privacy-conscious homeowners, small businesses, and sysadmins wanting an alternative to commercial NVRs
For about 3 years, I self-hosted my security camera system on the Synology surveillance station. It fit a lot of my needs, but I hated the hardware lock in. I was getting more and more frustrated with Synology's behavior, but I didn't find any alternatives I liked better.
So on Christmas 2025 I decided to put Claude Code to the test. I fully transitioned to this about two weeks later. I've been running 14 IP cameras doing 24/7 recording with live streaming and ML-powered detection.
The stack is FastAPI + React + PostgreSQL, orchestrated with Docker. Video is handled by FFmpeg with a single process per camera that does both live HLS streaming and MP4 recording simultaneously, so you don't burn multiple RTSP connections per camera.
It runs YOLO11 via ONNX Runtime on live HLS segments (no extra RTSP connections needed), uses background subtraction to skip static frames, and has a finite state machine that tracks object arrivals, departures, and state changes rather than just firing "person detected" over and over. Each event gets a snapshot with bounding boxes and an extracted video clip. There's also a Vision LLM integration that can describe what's happening in a scene.
Storage uses a tiered system (hot/warm/cold) with automatic migration, so recordings age off from fast local storage to larger drives and optionally to S3 (that part is still in-progress).
It supports GPU acceleration but also runs fine in CPU-only mode.
I know nothing about React, I've never been a front-end developer, so that's 99.99% Claude. I have edited some CSS though. I've personally done more work on the backend, but it's still mostly Claude. This is currently running behind my home VPN only, so the user management/authentication is kind of weak at the moment. I'd love feedback!
Screenshot object recognition beats simple coordinate replaying.
JWT-protected media endpoints, internal services binding to 127.0.0.1, and passthrough recording with hardware-accel show this is designed for real-world ops, not just a demo. The combination of a custom Python video engine plus a modern React/Vite UI makes it pleasant to use; still, it's competing in a crowded NVR space (Shinobi/ZoneMinder/etc.), and the project is in beta with an evolving DB schema so expect migration work on upgrades.
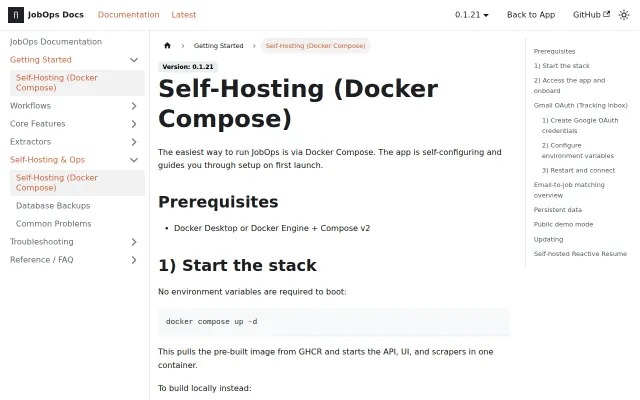
Combines three useful pieces into one local tool: board scraping, LLM-based fit scoring, and resume PDF generation via RxResume, with Gmail inbox linking for automatic post-apply tracking. The Docker-first onboarding and configurable LLM providers make it approachable for tinkerers, but extractor reliability, regional coverage, and scraping/ToS issues are the real tests — documentation and region-specific extractor robustness will make or break adoption.
Manifesto-heavy blog post claiming self-aware objects without visible code or demo.
Character.ai clone with privacy claims but no self-hosting option.
Uses a headless Playwright browser to render candidate privacy pages, extract both mailto links and inline addresses, rank candidates, and emit per-site JSON or plain email lists. Responsible-scraping defaults (robots.txt, request delay, resource blocking) are practical touches you don't always see in hobby scrapers. It stops at discovery — no contact-form parsing or automated request delivery — and Playwright's install/runtime overhead makes large-scale runs heavier than a simple crawler.