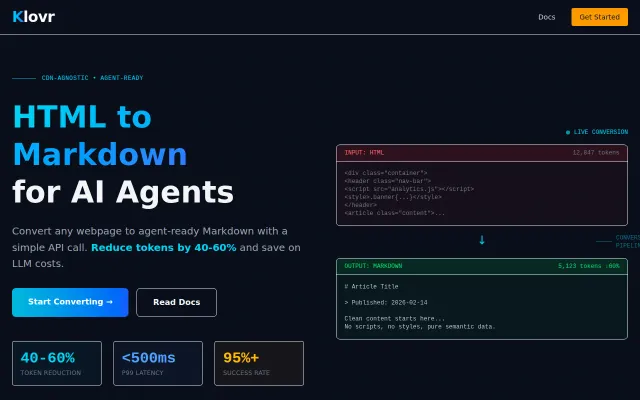
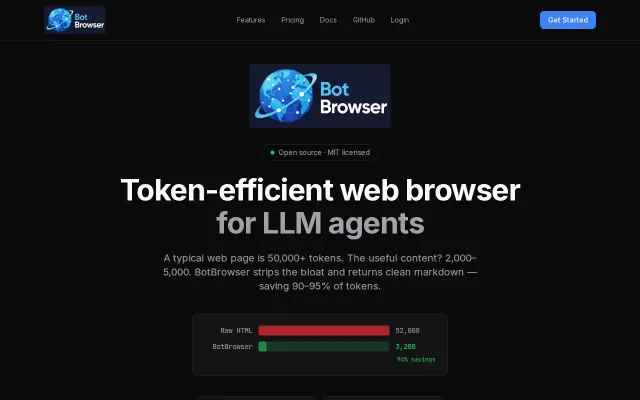
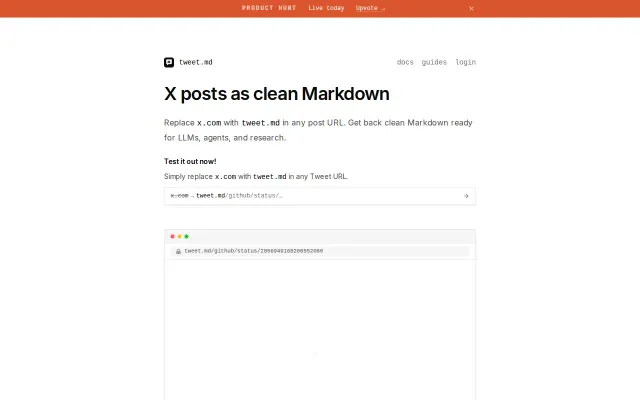
Hi HN! I shared LLMFeeder here 8 months ago when it was a simple one-click webpage-to-markdown tool. Since then, it's grown into something much more powerful, so I wanted to share the major updates.
The original problem: copying documentation/articles to feed into ChatGPT, Claude, or coding assistants like Cursor meant dealing with ads, popups, and navigation clutter and using web mcp server usually bloats the context with irrelevant stuff.
v2.1.0 adds several features specifically for LLM power users:
- Multi-tab support: The #1 requested feature. Select multiple tabs with Ctrl/Cmd+Shift+Click, then convert all at once. Options: copy merged, download merged, or download as ZIP with separate files per tab. Great for research sessions where you need context from multiple sources!
- Right-click context menus: No need to open the popup. Just right-click anywhere on a page → "Copy to Markdown". When multiple tabs are selected, you get batch options in the menu.
- Token counter: Real-time estimation using the GPT-4/Claude tokenizer (cl100k_base). Shows a progress bar with configurable context limits (4K, 8K, 16K, 32K) so you don't accidentally overflow your context window.
- Include links toggle: Strip URLs when you don't need them to save tokens. `[link text](https://...)` becomes just `link text`.
Everything still runs 100% client-side with zero tracking. The extension has grown to 1,000+ Chrome users and 200+ Firefox users.
Tech stack: Mozilla Readability.js for content extraction, Turndown.js for Markdown conversion, and JSZip for multi-tab archives.
Links:
- GitHub: https://github.com/jatinkrmalik/LLMFeeder
- Chrome: https://chromewebstore.google.com/detail/llmfeeder/cjjfhhapa...
- Firefox: https://addons.mozilla.org/en-US/firefox/addon/llmfeeder/
Would love feedback on what else would make the LLM context workflow smoother.
What's still painful about feeding content to AI assistants?