Productivity●●●Banger
Aside – Local meeting capture with vault-native AI distillation
Obsidian-native meeting tool that chains your vault as context for distillation.
Solve My ProblemDark HorseNiche Gem
jphorism
103mo ago
Bridges three tools academics already own, zero cloud lock-in, extracts highlights via wire protocol parsing.
Researchers, academics, and knowledge workers who use Zotero, reMarkable, and Obsidian.
Zotero plugins (native PDF tools) · ReadWise (highlights-to-notes, but closed ecosystem)
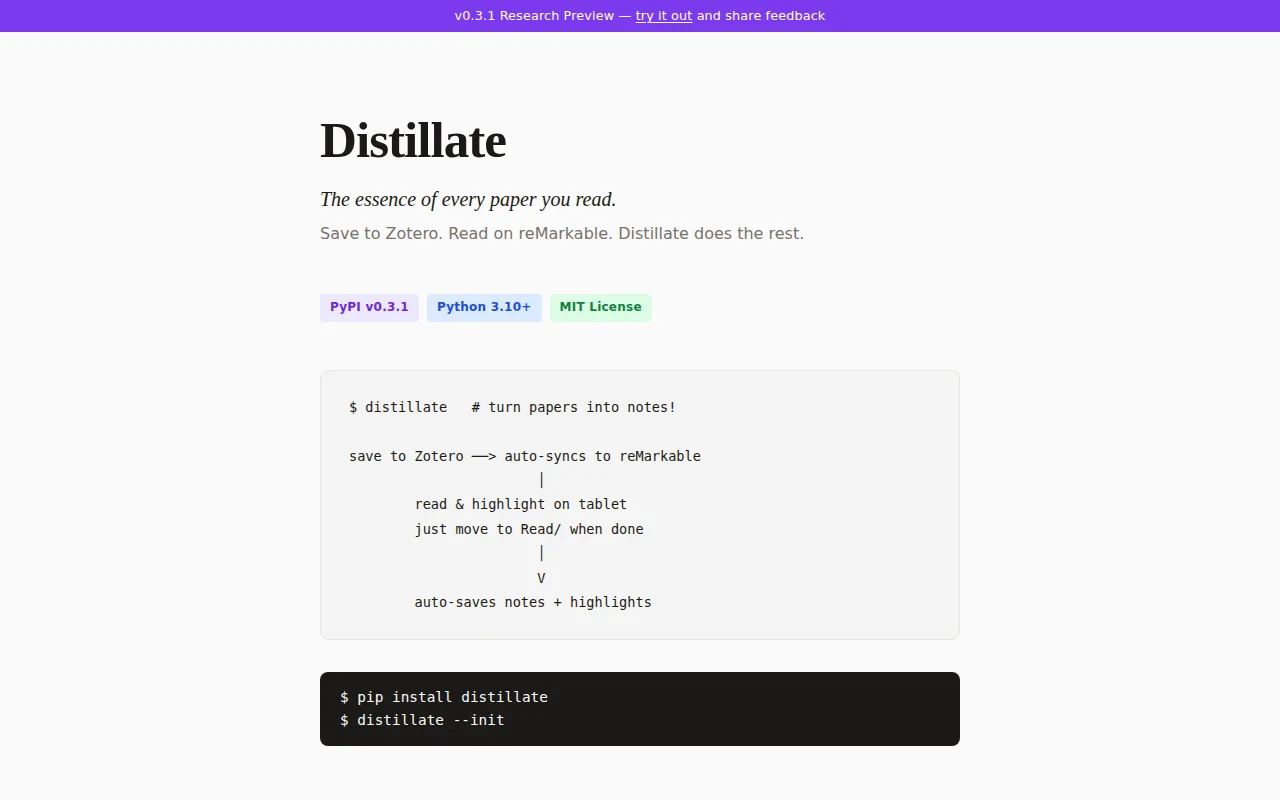
Distillate bridges the tools I already use: Zotero (literature management), reMarkable (reader + highlighter), and Obsidian (notes). It automates the whole pipeline:
$ distillate
save to Zotero ──> auto-syncs to reMarkable
│
read & highlight on tablet just move to Read/ when done
│
V
auto-saves notes + highlights
It polls Zotero for new papers, uploads PDFs to the reMarkable via rmapi, then watches for papers you've finished reading in your Read folder. When it finds one, it:- Parses .rm files using rmscene to extract highlighted text (GlyphRange items) - Searches for that text in the original PDF using PyMuPDF and adds highlight annotations - Enriches metadata from Semantic Scholar (publication date, venue, citations) - Creates a structured markdown note with metadata, highlights grouped by page, and the annotated PDF (I keep mine in an Obsidian vault)
The core workflow just needs Zotero and a reMarkable — no paid APIs, no cloud backend, your notes stay on your machine. Optional extras if you plug them in:
- AI summaries via Claude (one-liner + key learnings from your highlights) - Daily reading suggestions from your queue - Weekly email digest via Resend - Obsidian Bases database for tracking your reading
Stack: rmapi for reMarkable Cloud, rmscene for .rm parsing, PyMuPDF for PDF annotation. Python 3.10+, pip installable.
The trickiest part was highlight extraction: reMarkable stores highlighted text as GlyphRange items in a scene tree, and matching that text back to positions in the original PDF required fuzzy search with OCR cleanup, plus special merging logic for e.g. cross-page highlights. Happy to say it works well ~99% of the time now.
Install: pip install distillate && distillate --init
Code: https://github.com/rlacombe/distillate
Site: https://distillate.dev
I built this for myself but would love feedback, especially from other reMarkable + Zotero users. What's missing from your workflow? What else should I add?
Obsidian-native meeting tool that chains your vault as context for distillation.
LLM-filtered arXiv digest with Zotero PDF sync for robotics researchers.
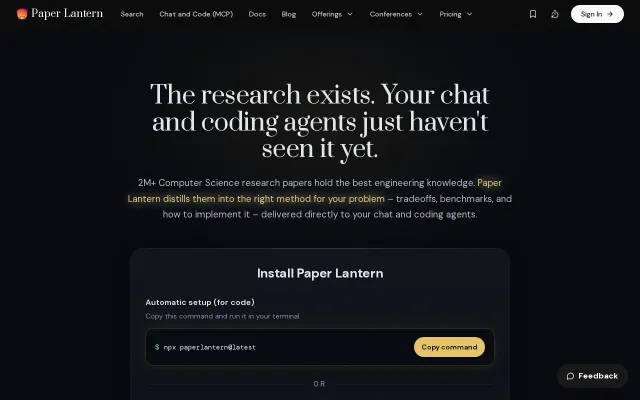
Coding agents search Stack Overflow; this serves them peer-reviewed techniques with benchmarks.
Bridges offline tablet notes into Claude's context—solves the second-brain connectivity gap.
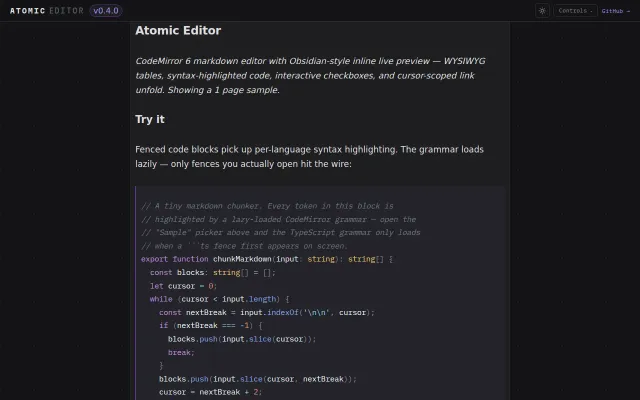
Lazy-loaded grammars only hit the wire when you open a fence.
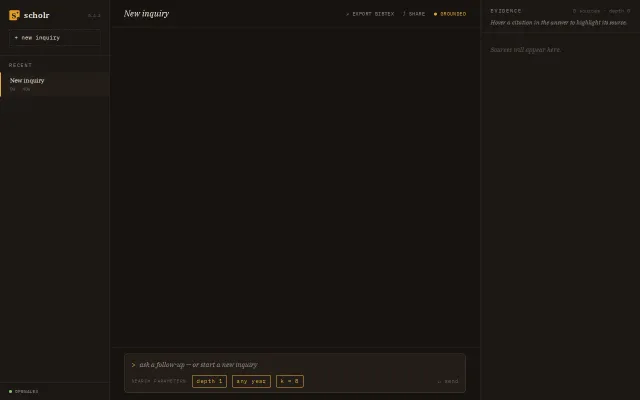
Citation-grounded synthesis beats generic RAG wrappers for academic rigor.