Infrastructure●●●Banger
See – searchable JSON compression, smaller than ZSTD (on our data)
Beats Zstd-19 on size, keeps JSON queryable without external indexes.
Big BrainWizardry
Tetsuro
314mo ago
Schema-aware JSON compression with millisecond lookups — cut transfer/storage while enabling exists /pos queries. (Demo + wheels; core is binary-only)
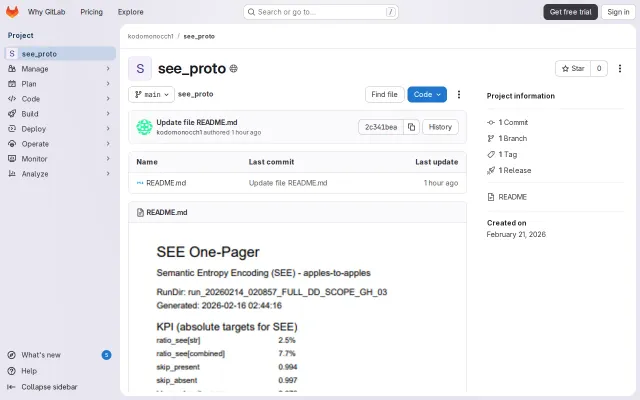
Searchable JSON compression at 7.7% with 0.085ms random lookups; skips 99% of pages.
Platform engineers, observability teams, data storage architects, storage-constrained environments
ParquetJS · ClickHouse · Zstandard (Zstd)
Goal: Reduce the “data tax” (storage/egress) and the “CPU tax” (decompress/parse) by keeping data searchable while compressed.
What’s different: - Page-based layout + Bloom filter skipping + a small directory index - Fast exists/pos/eq-style lookups without full decompression
Proof-first (no meeting required): - A 10-minute offline Demo Pack (wheel + sample .see + scripts + OnePager) - A DD Evidence Pack designed for reviewers (mismatch-zero checks, audit status, verification file list)
I’m exploring either: (A) acquisition (asset purchase), or (B) an exclusive license with a strategic buyer with a clear integration path. Evaluation slots are limited.
Repo + release assets are linked in the comments. Happy to answer technical questions here.
Beats Zstd-19 on size, keeps JSON queryable without external indexes.
Searchable JSON compression with page-level access is clever, but it's a pre-revenue tech asset, not a working product.
Schema-aware JSON compression stays searchable; reaches 7.7% vs Zstd's 13.7%.
Spec-first approach competing against LinkedIn and W3C Verifiable Credentials with no working implementation.
Fixes WHOIS's broken successor: one endpoint, consistent schema, handles multi-server routing automatically.
Detects breaking JSON schema changes and generates test data.