Open Source●●●Banger
Self-hosted static archive of 20 years of Hacker News
Runs 22GB of HN history entirely in-browser using lazy-loaded SQLite shards over WebAssembly.
Rabbit HoleZero to OneWizardry
keepamovin
111mo ago
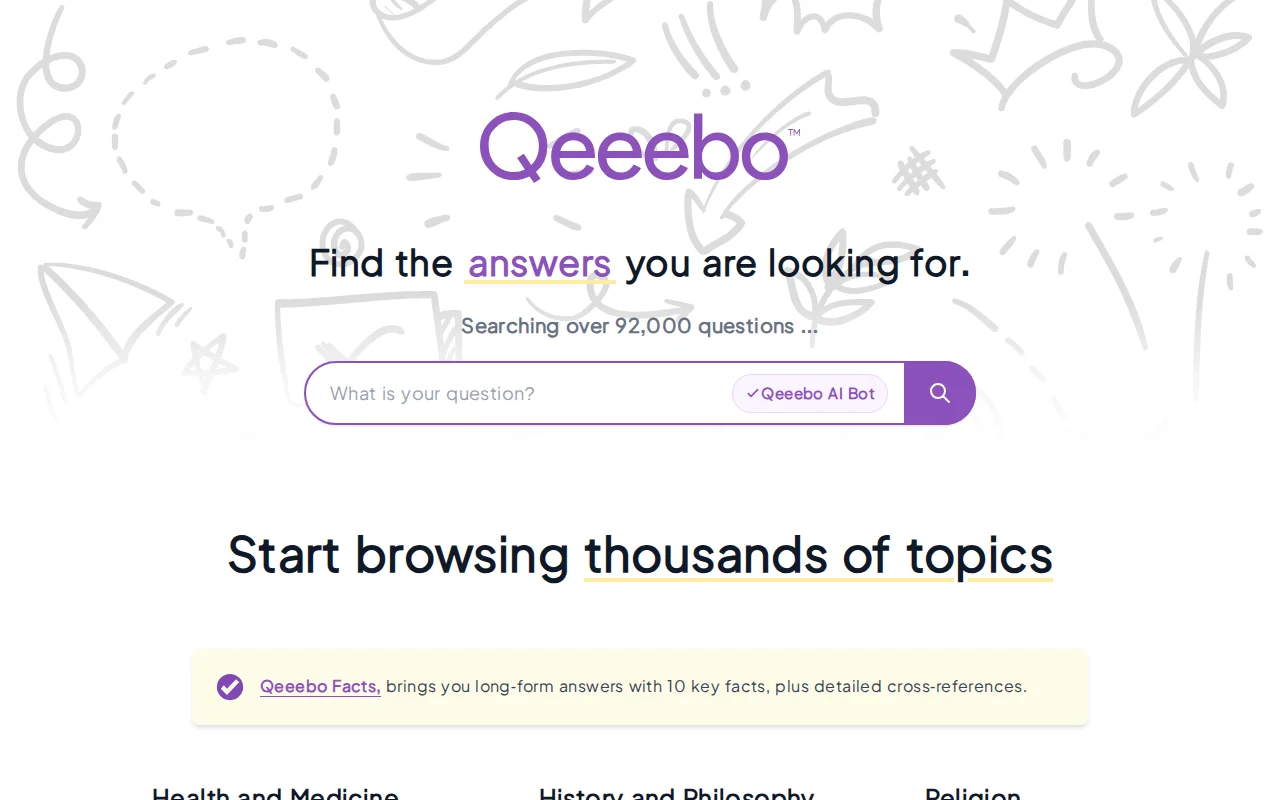
150M static Q&A pages on CDN, but answers are AI-generated and unvetted.
Students, researchers, and knowledge seekers looking for structured Q&A with citations and export options.
Wikipedia · Stack Overflow · ChatGPT
This month, we are releasing:
• 150+ million structured questions • 24.5 million topics • 171 million topic-question relationships • 18+ million paginated topic pages • 100% pre-rendered static HTML • No origin servers — served entirely via CDN
Each question includes: – A full answer – A summary – Structured citation formats (APA, MLA, Chicago, IEEE, etc.) – Export formats (BibTeX, RIS, JSON-LD, YAML)
The entire system is generated in independent segments (~45k pages each), built across parallel machines running Hugo, then uploaded via automated multi-threaded pipelines with full failure tracking.
Why build this?
Large Q&A platforms historically struggled with sustainability — especially when operating on database-backed, dynamically rendered systems. We wanted to explore whether extreme-scale static generation could reduce infrastructure cost while increasing long-term durability.
This isn’t positioned as a replacement for Wikipedia or Stack Overflow. Instead, it’s an experiment in permanence and cost-efficient knowledge hosting at very large scale.
Happy to answer technical questions.
Runs 22GB of HN history entirely in-browser using lazy-loaded SQLite shards over WebAssembly.
Blog post positioning a SaaS tool, not a product or project worthy of Show HN.
Grounds every answer in approved docs with citations, unlike generic RFP writers.
ProofPudding returns extraction results with explicit links back to the exact page and source text, supports native and scanned PDFs plus DOCX/images, and ships Python/TypeScript SDKs — handy for agents that need auditable facts. It’s a pragmatic product (per-extraction pricing and confidence scores are nice), but the market is crowded; I want clarity on underlying models, real-world accuracy numbers, and how it compares to Document AI/Textract in edge cases.
Multimodal RAG on SpaceX S-1 with source trails, but document Q&A is a crowded category.
Chat-with-codebase when Cursor, Sourcegraph, Continue already own this space.