AI/ML●●Solid
Ragprobe – measure RAG domain difficulty before deploying,no embeddings
Predicts RAG benchmark transfer failure using vocabulary specificity—no embeddings needed.
Big BrainNiche Gem
metawake
102mo ago
Legal RAG benchmark revealing embedding quality > LLM choice by 19-point margin.
AI researchers, legal tech builders, anyone evaluating RAG systems for legal applications
MTEB (Massive Text Embedding Benchmark) · MLEB (Massive Legal Embedding Benchmark) · BEIR
The key takeaways of our benchmark are: 1. Embedding models, not generative models, are the primary driver of RAG accuracy. Switching from a general-purpose embedder like OpenAI's Text Embedding 3 Large to a legal domain embedder like Kanon 2 Embedder can raise accuracy by ~19 points. 2. Hallucinations are often triggered by retrieval failures. Fix your retrieval stack, and, in most cases, you end up fixing hallucinations. 3. Once you have a solid legal retrieval engine, it doesn’t matter as much what generative model you use; GPT-5.2 and Gemini 3.1 Pro perform relatively similarly, with Gemini 3.1 Pro achieving slightly better accuracy at the cost of more hallucinations. 4. Google's latest LLM, Gemini 3.1 Pro, is actually a bit worse than its predecessor at legal RAG, achieving 79.3% accuracy instead of 80.3%.
These findings confirm what we already suspected, that information retrieval sets the ceiling on the accuracy of legal RAG systems. It doesn’t matter how smart you are, you aren’t going to magically know what the penalty is for speeding in California without access to an up-to-date copy of the California Vehicle Code.
Even still, to our knowledge, we’re the first to actually show this empirically.
Unfortunately, as we highlight in our write-up, high-quality open legal benchmarks like Legal RAG Bench and our earlier Massive Legal Embedding Benchmark (MLEB) are few and far between.
We point out, for example, that the popular Vals AI CaseLaw (v2) benchmark yields LLM rankings inexplicably and starkly different from ours while also failing to properly evaluate end-to-end RAG performance. Because CaseLaw (v2) is a private and proprietary benchmark, we are unable to confirm the source of the discrepancies we discovered, though we suspect they lie in a seriously flawed evaluation and labeling methodology.
In the interests of transparency, we have not only detailed exactly how we built Legal RAG Bench, but we’ve also released all of our data openly on Hugging Face here: https://huggingface.co/datasets/isaacus/legal-rag-bench/. We will also soon be publishing our write up as a paper.
Predicts RAG benchmark transfer failure using vocabulary specificity—no embeddings needed.
Tests agents on 700 policy docs and noisy voice calls where AgentBench stops.
Specialized legal models topping retrieval benchmarks when general LLMs hallucinate.
Naive prompts hallucinate history; structured knowledge injection raises accuracy from 12.5% to 83.3%.
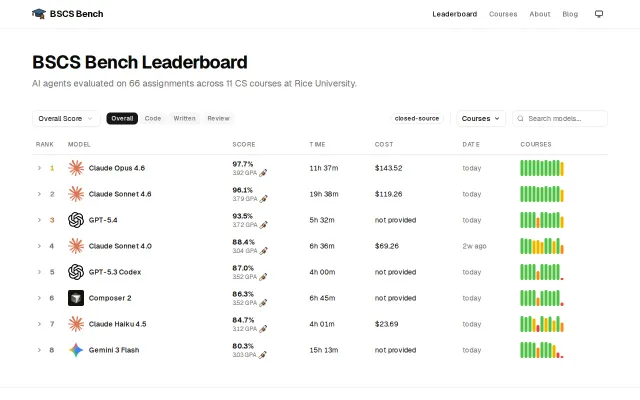
Real CS coursework beats synthetic coding benchmarks for model evaluation.
Unsupervised bug benchmark using agents as both attackers and defenders—novel scoring methodology.