AI/ML●●●Banger
Legal RAG Bench
Legal RAG benchmark revealing embedding quality > LLM choice by 19-point margin.
Big BrainNiche GemSolve My Problem
beowa
414mo ago
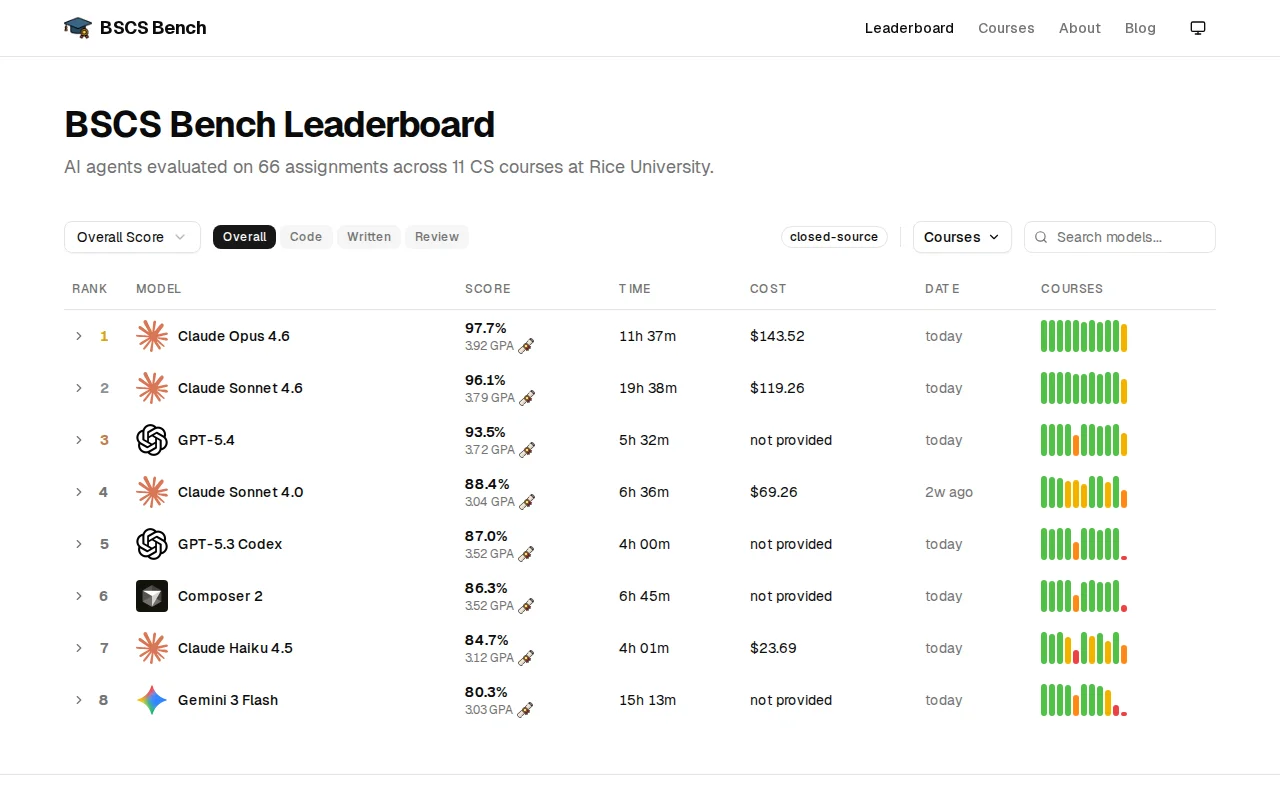
Real CS coursework beats synthetic coding benchmarks for model evaluation.
AI researchers, educators, and teams evaluating coding models
HumanEval · SWE-bench · LiveCodeBench
I also wrote a companion essay discussing the effects of these results on higher education as a whole: https://www.bscsbench.com/blog/no-calculators-please
Legal RAG benchmark revealing embedding quality > LLM choice by 19-point margin.
Unsupervised bug benchmark using agents as both attackers and defenders—novel scoring methodology.
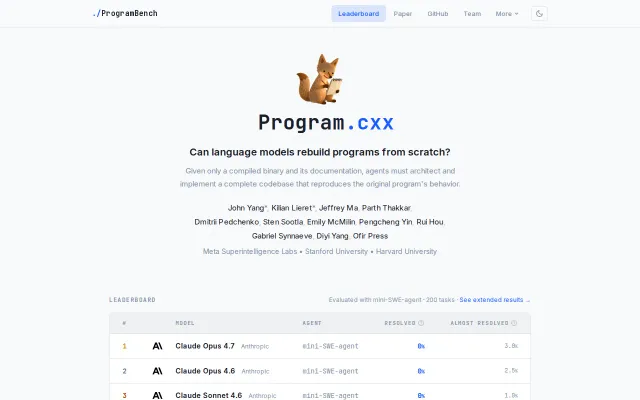
Agents fail completely at rebuilding binaries from scratch without source code.
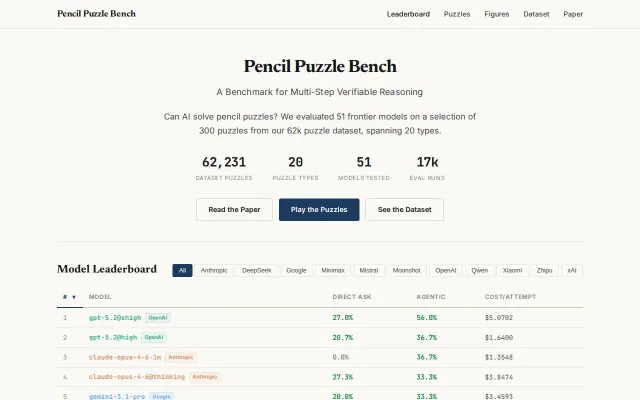
62k puzzle benchmark reveals reasoning depth, cost variance, and stark US vs China model gaps.
Syllabus-to-calendar automation sounds helpful, but Google Tasks, Canvas, and syllabus bots exist.
Interactive DuckDB-WASM benchmark beats static leaderboards for agentic SQL eval.