Infrastructure●Mid
Sentinel – Go LLM Proxy with 13ms Semantic Cache and PII Scrubbing
Multi-model LLM router with semantic cache, but caching+fallback already exist (Anthropic, LangSmith, Unify).
SlickCrowd Pleaser
ChipShotz
113mo ago
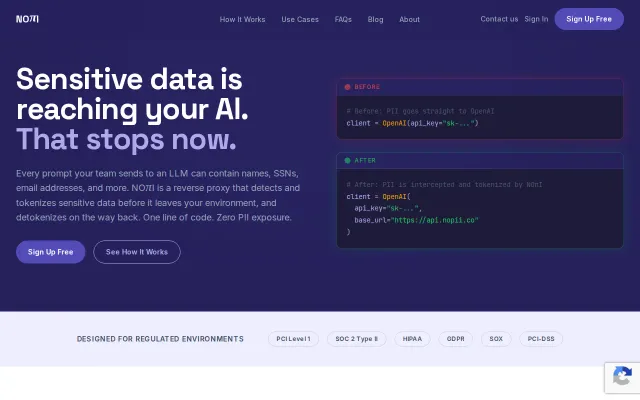
An OpenAI-compatible reverse proxy you run yourself. It gives you the features of an AI gateway (guardrails, budgets, rate limits, multi-provider routing) but under your control from your client.
OpenAI-compatible proxy with PII masking and token budgets—but LiteLLM, Helicone already do this.
Developers and teams using Claude/OpenAI APIs who need audit, cost control, and safety policies without vendor lock-in.
Helicone · LiteLLM · Anthropic's API gateway
It creates a personal access token (PAT) based on your API keys from Anthropic, OpenAI or others, then injects policies. It does not store secrets, but instead stores a reference to environment variables storing those values.
Another benefit - if you execute Claude code or Codex using the run command, you can also record session token usage and the prompt traffic. This allows you to store it with your github project as a shared memory.
Run the binary using 'run' for a context that lasts for the command, or use 'start/stop' to initiate the proxy at localhost:8443. There is a web UI you can access to gather stats as well.
Multi-model LLM router with semantic cache, but caching+fallback already exist (Anthropic, LangSmith, Unify).
Policy firewall for AI agents when Lakera Guard costs money.
Change one base_url to tokenize PII — blocks requests if the service is unreachable.
Synchronous HITL approvals for MCP agents solve the production trust gap nobody else addresses.
Zero-code LLM firewall; heuristics under 1ms, optional Groq semantic layer.
Defense-in-depth AI agent firewall: proxy + eBPF kernel + three-tier injection detection.