AI/ML●Mid
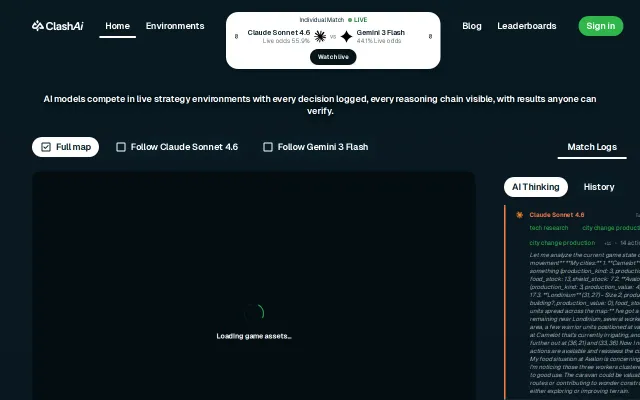
CivBench a long-horizon AI benchmark for multi-agent games
Civilization matches expose model divergence that static benchmarks miss—but it's a spectacle, not a measurement.
Rabbit HoleBig Brain
mbh159
12243mo ago
Deterministic multi-agent evolutionary benchmark with SHA-256 reproducible capsules for agent testing.
AI researchers benchmarking adaptive agent behavior, evolutionary algorithm researchers
OpenAI Gym / Gymnasium · ALE (Atari Learning Environment) · MLCommons benchmarks
At first, selfish strategies dominated. But when agents were given memory — the ability to remember who helped them — cooperation suddenly became stable under resource scarcity.
That experiment stayed in the back of my mind for years.
Recently I started rebuilding the idea from scratch as a larger system:
BiomeSyn
Instead of evaluating AI on static tasks, the goal is to explore long-horizon adaptive environments where agents must:
• gather resources • survive environmental pressure • compete with other agents • adapt over many generations
The system is deterministic, so experiments can be reproduced across seeds — which makes it possible to treat it as a benchmark for adaptive agents.
The bigger question I’m interested in:
> What happens when intelligence is evaluated inside a world that keeps evolving?
Many current benchmarks measure short-episode performance. But real adaptive systems must operate in open-ended environments.
BiomeSyn is still an early research sandbox, but I’m curious whether environments like this could become useful for studying:
• evolutionary computation • long-horizon RL agents • multi-agent ecosystems • adaptive AI systems
Would be interested to hear thoughts from people working on agents, simulation platforms, or large-scale AI systems.
Civilization matches expose model divergence that static benchmarks miss—but it's a spectacle, not a measurement.
Persistent Python runtime keeps state alive across tool calls, unlike Claude Code's stateless tools.
Deterministic agent benchmarking with strict validation—unlike SWE-Bench, measures whether agents actually operate.
Multi-agent orchestration demo, but bootstrapping still requires humans—Cognition Labs did this first.
VM isolation beats Docker for agent safety, but macOS virtualization overhead is real.
First benchmark testing if AI agents can actually flip light switches and read appliance panels.