AI/ML●Mid
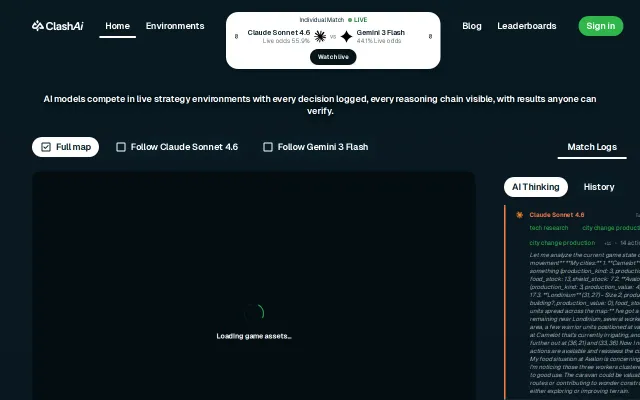
CivBench a long-horizon AI benchmark for multi-agent games
Civilization matches expose model divergence that static benchmarks miss—but it's a spectacle, not a measurement.
Rabbit HoleBig Brain
mbh159
12243mo ago
First benchmark testing if AI agents can actually flip light switches and read appliance panels.
Robotics researchers and embodied AI developers
BIG-bench · AgentBench · VLA benchmarks
Civilization matches expose model divergence that static benchmarks miss—but it's a spectacle, not a measurement.
Persistent Python runtime keeps state alive across tool calls, unlike Claude Code's stateless tools.
Deterministic multi-agent evolutionary benchmark with SHA-256 reproducible capsules for agent testing.
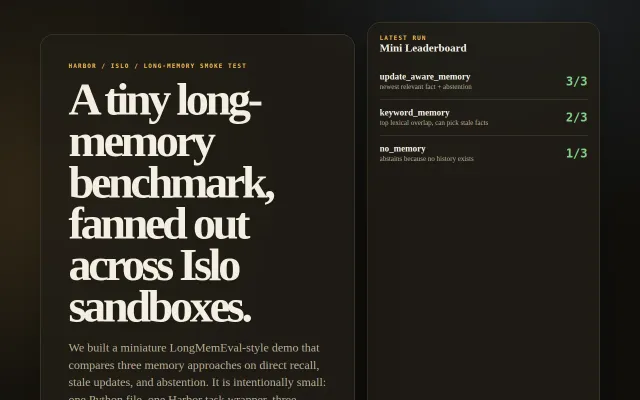
Compresses long-memory evaluation into three questions testing recall, updates, and abstention.
First benchmark testing structured requirements on complex greenfield agent tasks.
Benchmarks OpenCode models locally, but lacks preloaded datasets and only works with configured OpenAI-compatible APIs.