Security●●●Banger
Plyra-guard – intercepts AI agent tool calls before execution
Sub-2ms policy guard for agent tool calls—real safety layer where none existed.
Solve My ProblemWizardry
plyra
103mo ago
Deterministic policy matrices block AI agents from executing dangerous API calls.
AI Agent Developers
Guardrails AI · Lakera Guard · Open Policy Agent
Instead of relying only on prompts or output filtering, this introduces an authorization layer that evaluates whether an AI action should be allowed before it runs.
Each requested action is analyzed for signals such as:
• financial actions • external communications • data exports • system modification • destructive operations
Based on the detected signals and required authorization layers, the harness determines whether the action should PASS or DENY.
Example output:
Running 14 tests...
[1/14] financial_commitment -> DENY [2/14] send_external_email -> DENY [3/14] deploy_to_production -> DENY [14/14] general_information -> PASS
Every evaluation produces an auditable record including:
• detected signals • required authorizations • PASS / DENY decision
The goal is to explore what a deterministic execution governance layer might look like for AI systems interacting with real environments.
Demo video walkthrough: https://www.linkedin.com/feed/update/urn:li:activity:7436787... Repository:
https://github.com/celestinestudiosllc/ai-action-authorizati...
Curious how others building agent systems or AI runtimes are approaching execution authorization.
Sub-2ms policy guard for agent tool calls—real safety layer where none existed.
HarmActionsEval benchmark proves GPT and Claude fail at blocking harmful tool use.
Fail-closed MCP gateway with formal verification and MCPSEC benchmark suite.
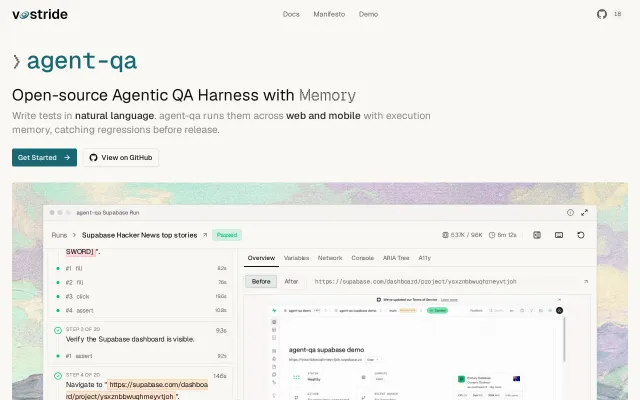
Self-healing tests that remember UI changes so you stop fixing broken selectors.
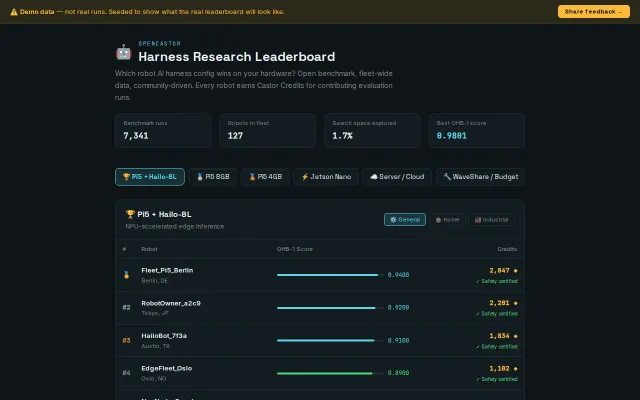
263k config search space benchmarked across robot fleets—nothing like this exists for robotics AI.
Finally forces AI agents to prove their work with real test gates instead of hallucinated confidence.