Developer Tools●Mid
FC-Eval – CLI to Benchmark Local or Cloud LLMs on Function Calling
AST-based validation for function calling tests, but BFCL already covers this ground.
Ship ItNiche Gem
gauravvij137
303mo ago
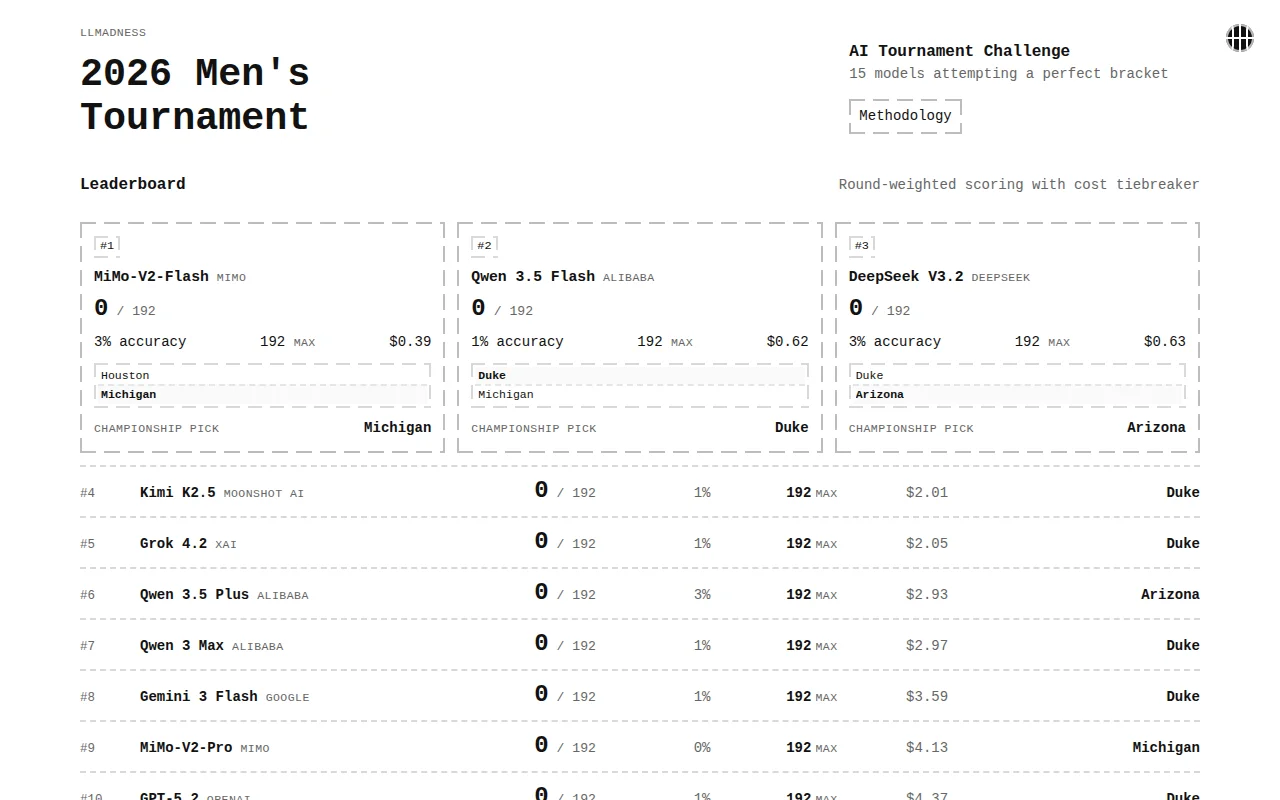
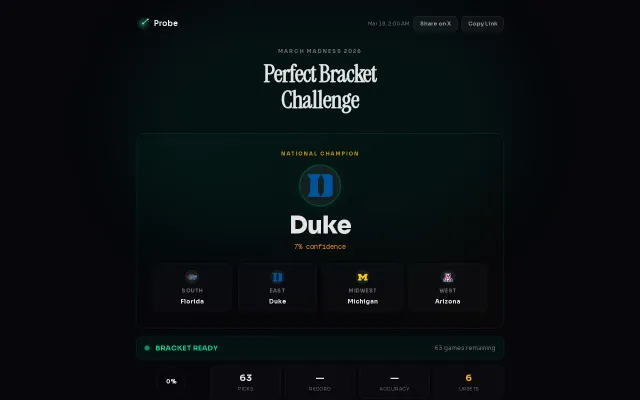
Claude Opus spent $59.55 versus MiMo-Flash at $0.39 for identical bracket predictions.
Developers evaluating LLMs, AI researchers
LMArena · Artificial Analysis · Vellum
After playing around a bit with the format, I went with the following setup:
- 63 single-game predictions v. full one-shot bracket
- Maxed out at 10 tool calls per game
- Upset-specific instruction in the system prompt
- Exponential scoring by round (1, 2, 4, 8, 16, 32)
There were some interesting learnings:
- Unsurprisingly, most brackets are close to chalk. Very few significant upsets were predicted.
- There was a HUGE cost and token disparity with the exact same setup and constraints. Both Claude models spent over $40 to fill in the bracket while MiMo-V2-Flash spent $0.39. I spent a total of $138.69 on all 15 model runs.
- There was also a big disparity in speed. Claude Opus 4.6 took almost 2 full days to finish the 2 play-ins and 63 bracket games. Qwen 3.5 Flash took under 10 minutes.
- Even when given the tournament year (2026), multiple models pulled in information from previous years. Claude seemed to be the biggest offender, really wanting Cooper Flagg to be on this year's Duke team.
This was a really fun way to combine two of my interests and I'm excited to see how the models perform over the coming weeks. You can click into each bracket node to see the full model trace and rationale behind the picks.
The stack is Typescript, Next.js, React, and raw CSS. No DB, everything stored in static JSON files. After each game, I update the actual results and re-deploy via GitHub Pages.
I wanted to work as fast as possible since the brackets lock today so almost all of the code was AI-generated (shocker).
Hope you enjoy checking it out!
AST-based validation for function calling tests, but BFCL already covers this ground.
Cache-aware LLM eval with self-hosted model support beats Ragas on flexibility.
Polished bracket tracker but KenPom already does predictions without the agent buzz.
Interesting eval philosophy, but this is a blog post with no shipped code or tool.
Run your own data against GPT-5 and Llama to pick the winner.
ESPN bracket simulator with live probability updates when FiveThirtyEight already does this.