AI/ML●●Solid
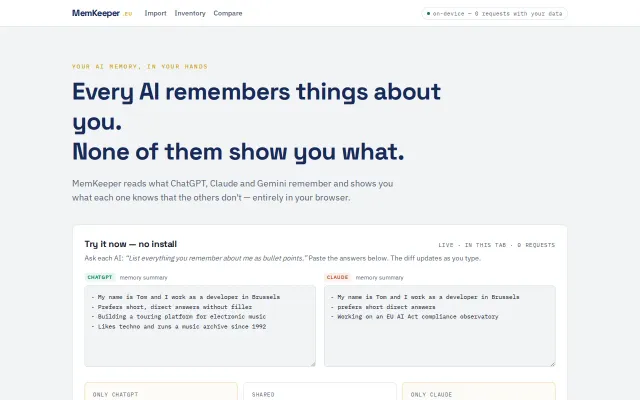
See what your AIs know about you that the others don't
In-browser diff shows what ChatGPT knows that Claude doesn't about you.
Solve My ProblemCozy
tomtom1977
2111d ago
Replaces stitching Langfuse and promptfoo together with one unified eval dashboard.
AI engineers and ML teams shipping LLM applications
LangSmith · Arize Phoenix · Promptfoo
EvalsHub does all of it in one place. Automatic production scoring, red teaming, prompt versioning, and CI/CD integration. Zero to full eval coverage in 30 minutes.
Would love brutal feedback from anyone shipping AI in production.
evalshub.ai
In-browser diff shows what ChatGPT knows that Claude doesn't about you.
Langfuse/Helicone angle—LLM-as-judge quality scoring—but no live product or differentiation yet.
Free audit funnel for AI observability when LangSmith and Helicone already do this.
Replays agent traces step-by-step to pinpoint exact failure turns automatically.
Iteratively improves agent harnesses from 67% to 87% on tau-bench using production traces.
Sentry-to-PR pipeline writes failing tests first, then fixes the bug.