Developer Tools●Mid
Agent-evals – Claude skill to build your own evals
Claude Skill for agent evals, but LangSmith and Arize already own this.
Solve My Problem
sauercrowd
911mo ago
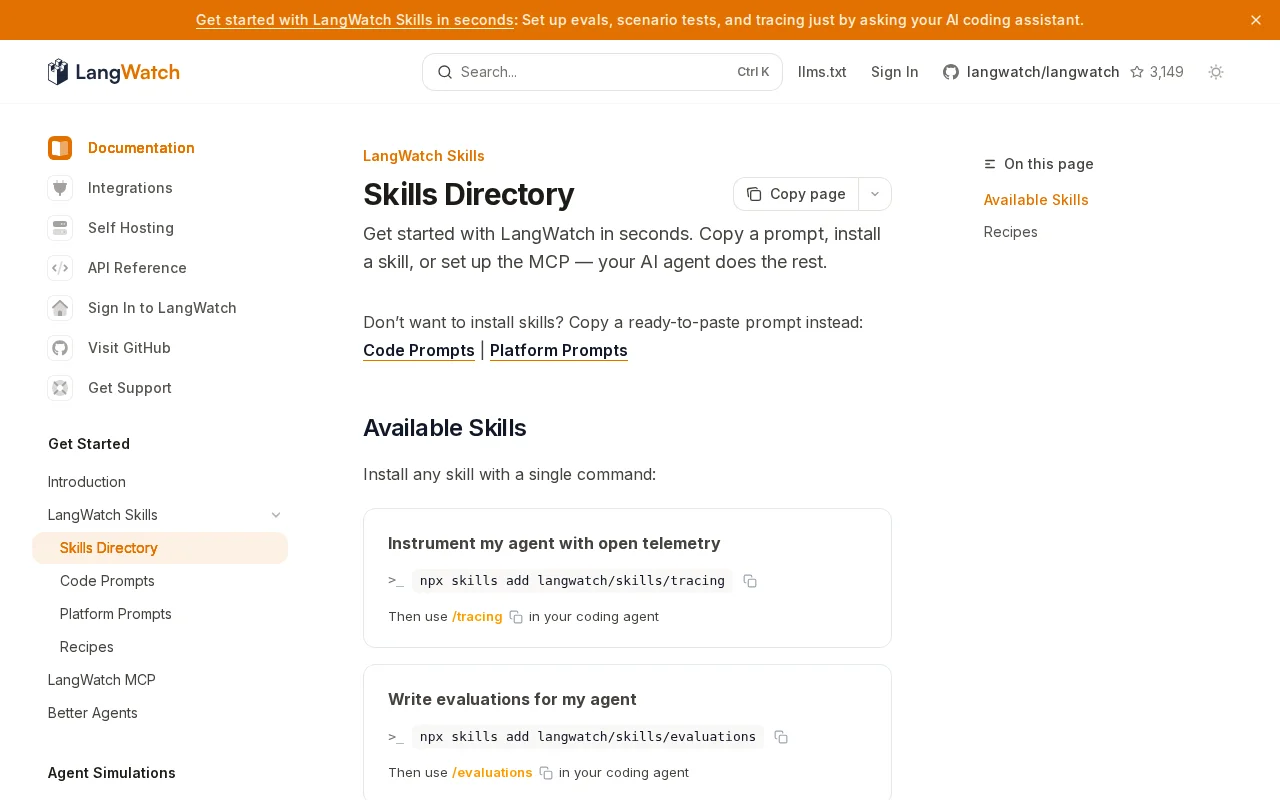
Install eval pipelines via npm instead of reading docs, saving hours of setup.
AI engineers, LLM application developers
LangSmith · Arize Phoenix · Helicone
I'm Rogerio, co-founder of LangWatch
This past month we've completely changed the way we onboard new customers now on LangWatch, instead of giving them instructions on how to instrument, cookbooks or UIs to build evals, or docs on how to write Scenario agent simulation tests, we simply give them skills now, or ready to copy-and-paste prompts.
This has reduced our onboarding time to only a few minutes, no more postponing evals because other priorities gets in the way.
We have now skills for everything for managing your agent lifecycle:
"Instrument my agent with open telemetry" "Write evaluations for my agent" "Write scenario tests and a CI pipeline for my agent" "Version my prompts"
and even more targeted recipes
"Check my agent doesn't give prescriptive advice" "Generate an evaluation dataset from my RAG knowledge base" "Test my CLI is well usable by other AI agents"
Check out more on LangWatch Skills directory above and lmk what you think
Claude Skill for agent evals, but LangSmith and Arize already own this.
Structured eval workflow for Claude Code when LangSmith and Braintrust already exist.
Terminal-native prompt evals with diff proposals beats web dashboards.
Agent-native eval workflow beats LangSmith's manual dashboard setup.
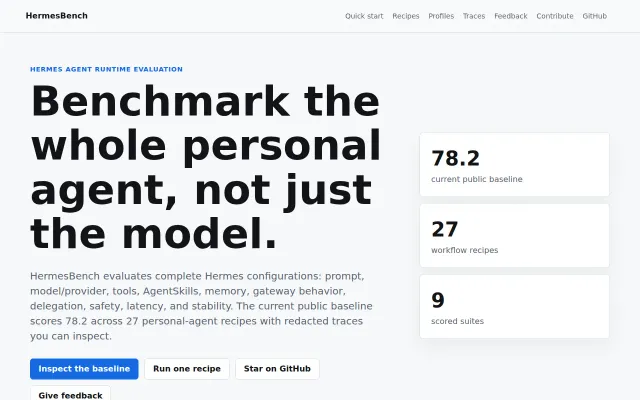
Whole-agent evals beat model-only benchmarks, but only one baseline published so far.
Lightweight A/B testing for SKILL.md files when LangSmith feels too heavy.