Developer Tools●●Solid
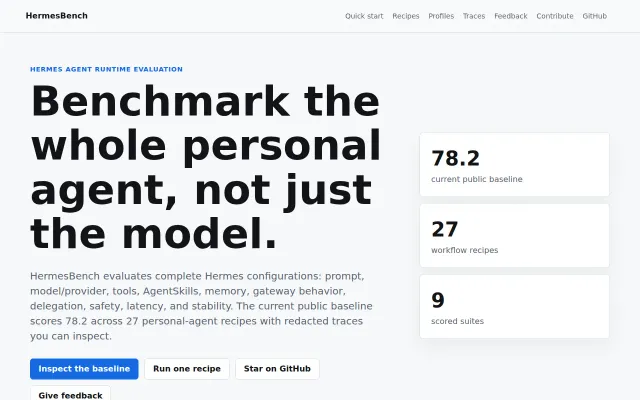
HermesBench – workflow reliability evals for personal AI agents
Whole-agent evals beat model-only benchmarks, but only one baseline published so far.
Big BrainShip It
verkyyi26
2022d ago
Claude Code for prompt eval
Terminal-native prompt evals with diff proposals beats web dashboards.
LLM developers, prompt engineers
LangSmith · Promptfoo · Arize Phoenix
Whole-agent evals beat model-only benchmarks, but only one baseline published so far.
Claude Skill for agent evals, but LangSmith and Arize already own this.
Fascinating art experiment, but more novelty than tool developers would actually use.
Install eval pipelines via npm instead of reading docs, saving hours of setup.
Lightweight A/B testing for SKILL.md files when LangSmith feels too heavy.
Automated rollback on regression is a killer feature LangSmith doesn't have.