AI/ML●●●Banger
Auto LLM Ranker – Describe a task in English and get ranked models
Task-specific LLM benchmarking beats generic leaderboards that ignore your actual workload.
Big BrainDark HorseZero to One
gauravvij137
303mo ago
Research article revealing few-shot collapse patterns, not a usable tool or product.
ML engineers, researchers evaluating LLM prompting strategies
LMSys Chatbot Arena · Hugging Face Open LLM Leaderboard
1. Few-shot can cause collapse: Gemini 3 Flash scored 93% at zero-shot on route optimization, then crashed to 30% at 8-shot. Same model family (Gemma 3 27B, local) stayed stable at 90%.
2. Most models benefit from few-shot: On classification, all models scored 0-20% at zero-shot. At 8-shot, scores spread from 27% to 80%. Zero-shot benchmarks would have led to the wrong model choice.
3. Task mismatch ≠ collapse: Reasoning-specialized models scored low on summarization regardless of shot count. They're not "collapsing" — they're just not suited for the task.
A 27B local model (Gemma 3) matched Claude Haiku's adaptation efficiency (AUC 0.814 vs 0.815). The 12-model results are included as default demo data — explore the patterns without API keys.
Article: https://dev.to/shuntarookuma/i-tested-12-llms-with-few-shot-...
GitHub (MIT): https://github.com/ShuntaroOkuma/adapt-gauge-core
Task-specific LLM benchmarking beats generic leaderboards that ignore your actual workload.
Rigorous benchmark methodology, but it's research not a tool you can use.
Opposite-narrator test catches models agreeing with both sides of same dispute.
Postman for local LLMs with LLM-as-Judge and Elo ratings built in.
Deterministic agent benchmarking with strict validation—unlike SWE-Bench, measures whether agents actually operate.
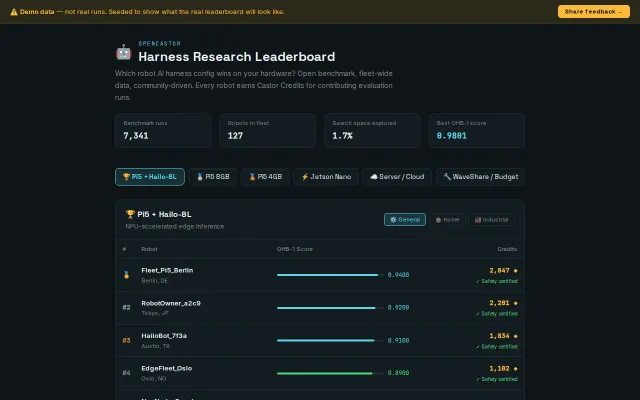
263k config search space benchmarked across robot fleets—nothing like this exists for robotics AI.