AI/ML●●●Banger

A new benchmark for testing LLMs for deterministic outputs
Finally separates JSON validity from actual value hallucination in LLM outputs.
Big BrainSolve My Problem
khurdula
60301mo ago
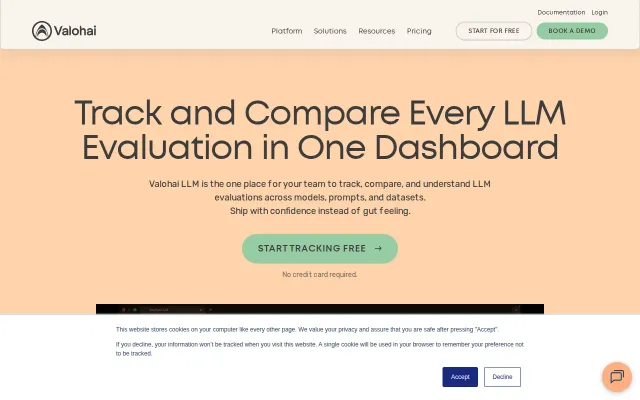
Evaluate structured LLM outputs with precision. Compare model outputs against expected schemas and values — row by row.
Schema conformance checks beat generic text evals for JSON-heavy LLM pipelines.
AI engineers building structured output pipelines
LangSmith · Ragas · Arize Phoenix
Finally separates JSON validity from actual value hallucination in LLM outputs.
Streams evals from a tiny Python client into a shared dashboard and lets you run parameter sweeps and compare up to six configurations with radar/bar charts and scorecards — exactly the sort of tooling that stops results getting lost in notebooks. Useful, pragmatic product for teams who repeatedly evaluate models, but it's competing with general observability/experiment trackers (W&B, Neptune) and will need strong integrations and metric flexibility to stand out.
DataFrame diffing for Polars with ASCII output when pandas comparisons fall short.
Phoenix LiveView embedding beats switching to LangSmith for Elixir teams.
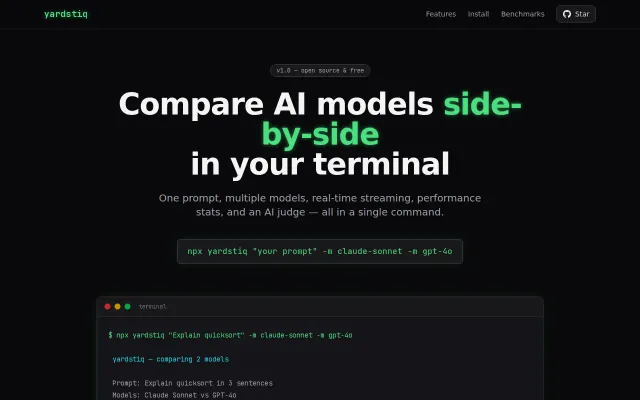
One-command model comparison with real-time streaming and performance metrics beats tab-switching.
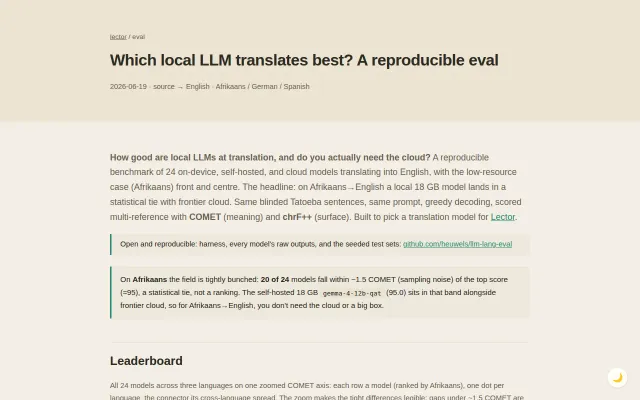
Local 18 GB Gemma ties frontier cloud on Afrikaans translation.