Developer Tools●Mid
OpenCode Benchmark Dashboard
Benchmarks OpenCode models locally, but lacks preloaded datasets and only works with configured OpenAI-compatible APIs.
Niche Gem
grigio
103mo ago
Yet another prompt benchmarking UI when Promptfoo and LangSmith already exist.
Prompt engineers and developers testing LLM performance
Promptfoo · LangSmith · Braintrust
Benchmarks OpenCode models locally, but lacks preloaded datasets and only works with configured OpenAI-compatible APIs.
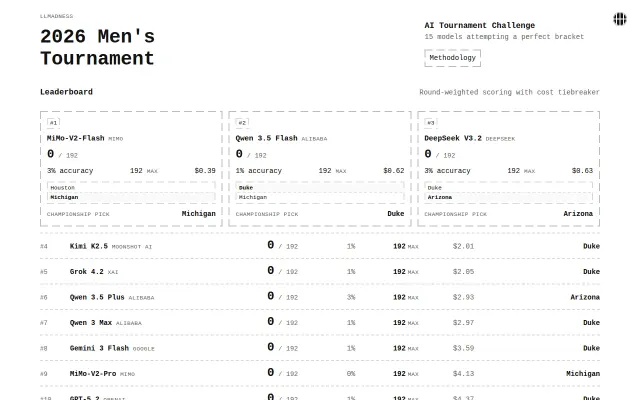
Claude Opus spent $59.55 versus MiMo-Flash at $0.39 for identical bracket predictions.
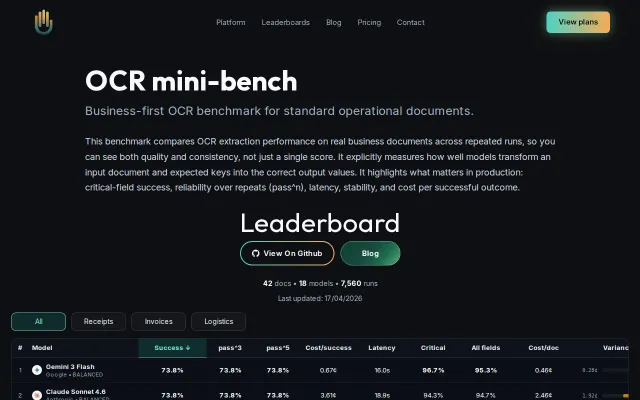
7,560 runs proving cheaper models beat expensive ones on production OCR tasks.
LLM cost optimizer, but Anthropic's batch API and local quantization solve this cheaper.
Quick terminal cost compare—but pricing dashboards (Anthropic console, OpenAI API usage) already do this.
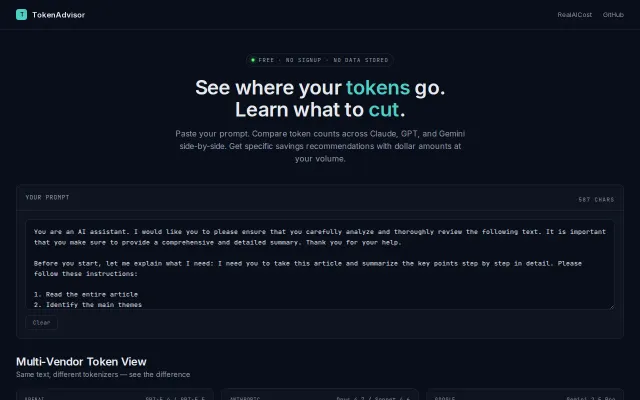
Multi-vendor token comparison with specific cut recommendations and dollar savings at scale.