Developer Tools●●Solid
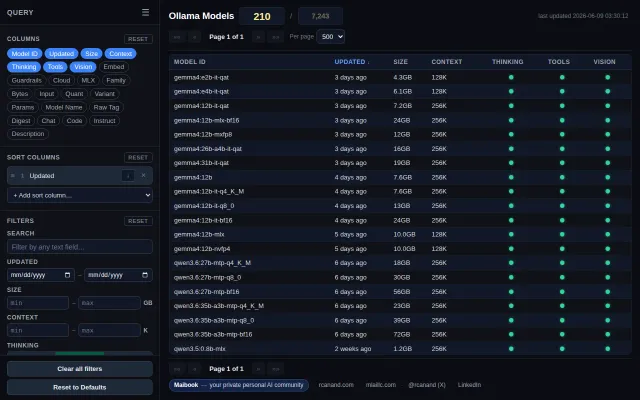
Ollama Dash – autoupdating dashboard for Ollama Models
Better model discovery than the official Ollama library with auto-updating capability filters.
Solve My ProblemSlick
rcanand2025
2311d ago
2500+ VLM benchmarks, auto-updated daily from arXiv
Daily arXiv scraping with Claude classification beats manual curation.
ML researchers and VLM developers tracking evaluation methods
Papers With Code · HuggingFace Datasets
Vision tasks vary quite a lot from one to another. For example:
- vision tasks that require high-level semantic understanding of the image. Models do quite well in them. Popular general benchmarks like MMMU are good for that. - visual reasoning tasks where VLMs are given a visual puzzle (think IQ-style test). VLMs perform quite poorly on them. Barely above a random guess. Benchmarks such as VisuLogic are designed for this. - visual counting tasks. Models only get it right about 20% of the times. But they’re getting better. Evals such as UNICBench test 21+ VLMs across counting tasks with varying levels of difficulty.
Compiled a list of 2.5k+ vision benchmarks with data links and high-level summary that auto-updates every day with new benchmarks.
Better model discovery than the official Ollama library with auto-updating capability filters.
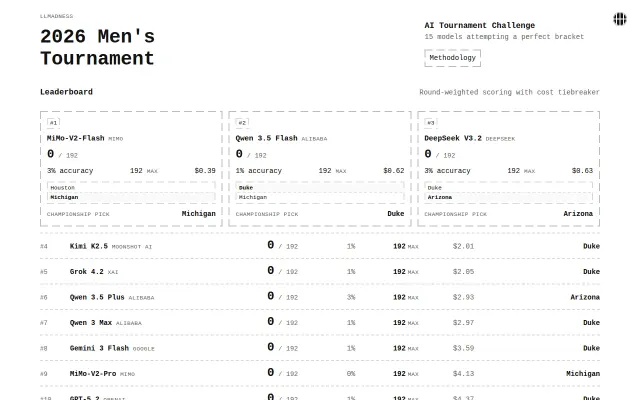
Claude Opus spent $59.55 versus MiMo-Flash at $0.39 for identical bracket predictions.
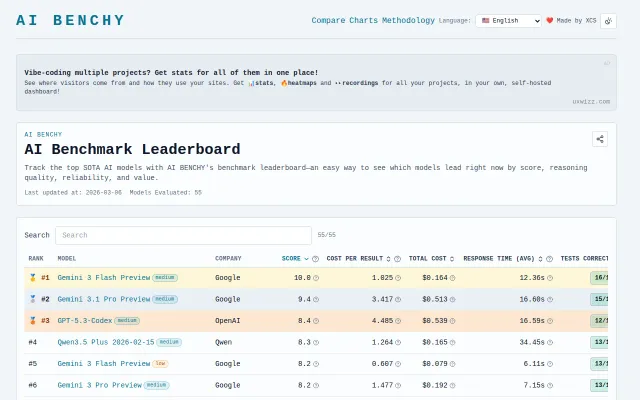
Clean leaderboard, but LMSys and HELM already solve model benchmarking comprehensively.
Run your own data against GPT-5 and Llama to pick the winner.
Interactive DuckDB-WASM benchmark beats static leaderboards for agentic SQL eval.
Interesting eval philosophy, but this is a blog post with no shipped code or tool.