AI/ML●●●Banger
LOAB – AI agents get decisions right but skip the process [pdf]
Frontier models hit 67-75% outcome accuracy but only 25-42% on process compliance.
Big BrainBold Bet
shubh-chat
103mo ago
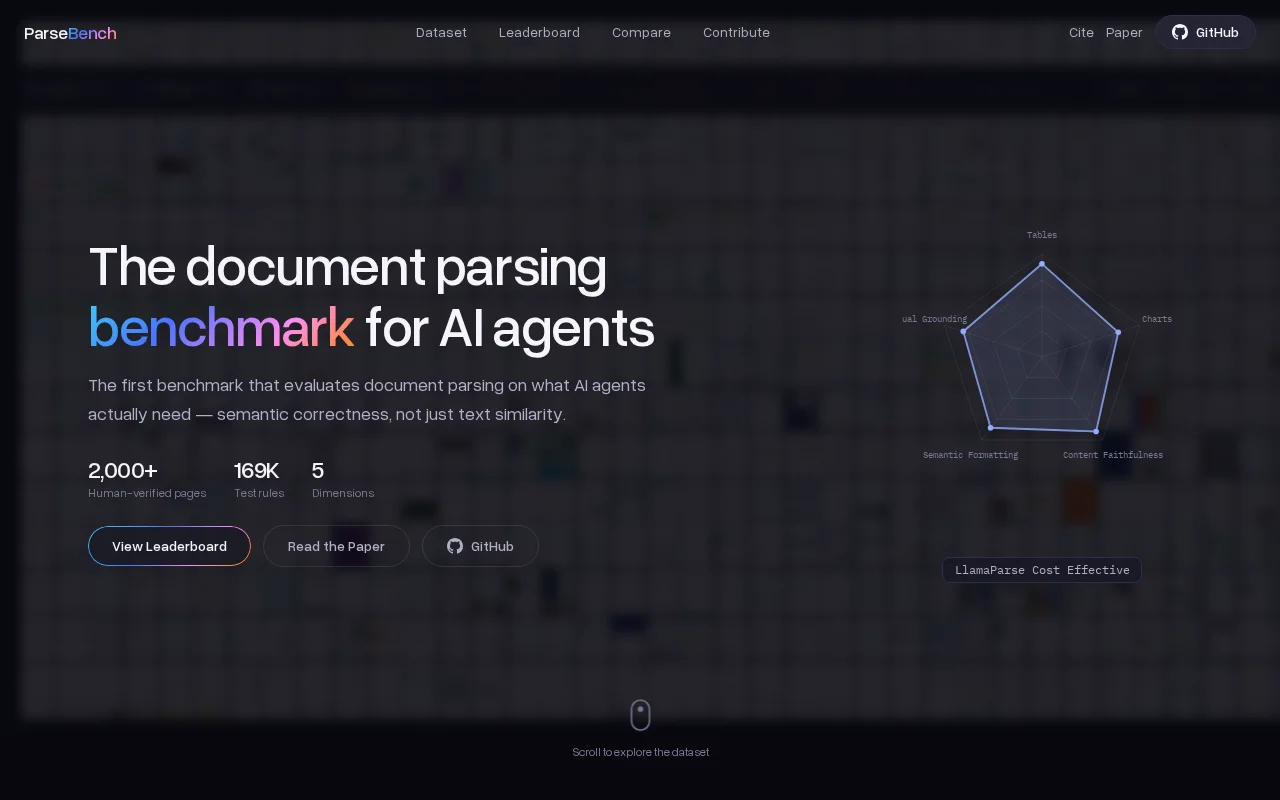
First benchmark measuring semantic correctness over text similarity for document parsing.
AI developers, document parsing teams, ML engineers
HELM · GLUE
Frontier models hit 67-75% outcome accuracy but only 25-42% on process compliance.
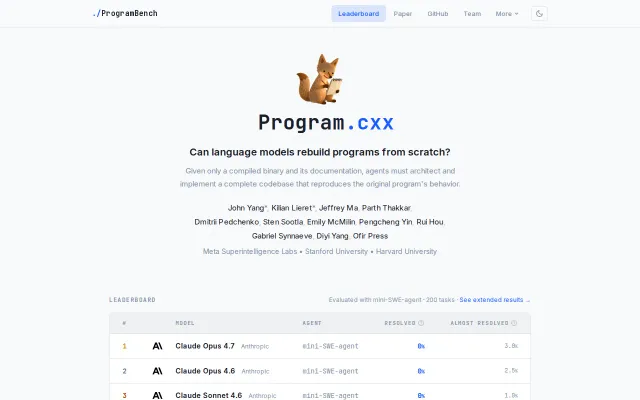
Agents fail completely at rebuilding binaries from scratch without source code.
LlamaIndex open-sources their parser core, but LlamaParse cloud still handles complex layouts.
Tests agents on 700 policy docs and noisy voice calls where AgentBench stops.
Unsupervised bug benchmark using agents as both attackers and defenders—novel scoring methodology.
Interactive DuckDB-WASM benchmark beats static leaderboards for agentic SQL eval.