Open Source●●Solid
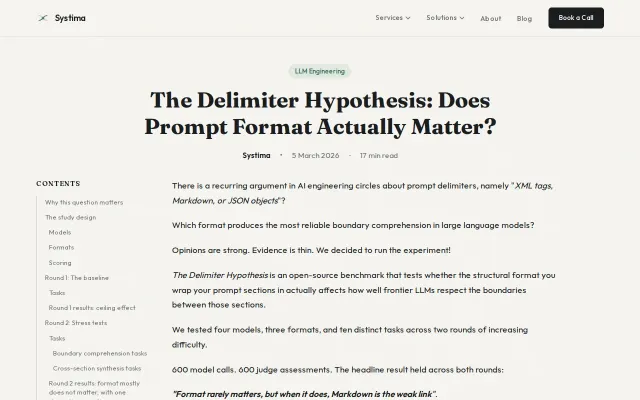
XML, Markdown, or JSON: Which gives LLMs the most reliable boundaries?
Settles the delimiter format debate with data—Markdown fails under adversarial inputs on MiniMax.
Big Brain
systima
323mo ago
Transparent benchmark for data analysis LLMs with verifiable notebook artifacts.
Data scientists, AI engineers building analysis agents
LMSys Chatbot Arena · AgentBench · LangSmith Evaluators
Settles the delimiter format debate with data—Markdown fails under adversarial inputs on MiniMax.
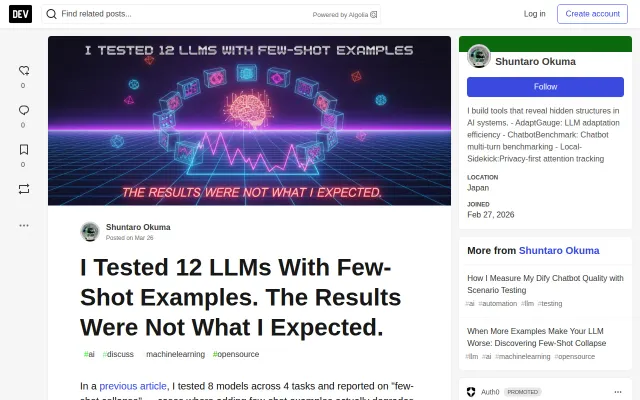
Research article revealing few-shot collapse patterns, not a usable tool or product.
Benchmarks OpenCode models locally, but lacks preloaded datasets and only works with configured OpenAI-compatible APIs.
Task-specific LLM benchmarking beats generic leaderboards that ignore your actual workload.
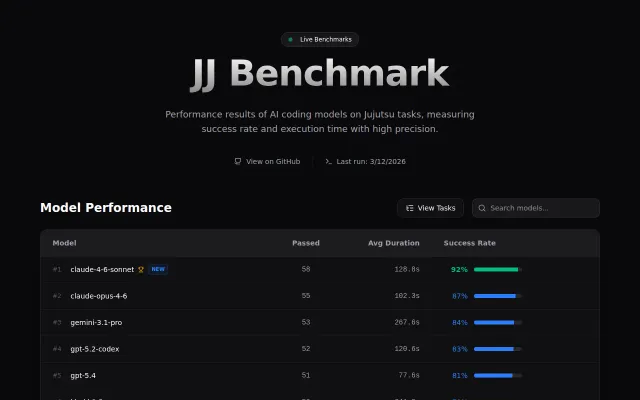
AI benchmarking for jj CLI when LMSys and HuggingFace already dominate the space.
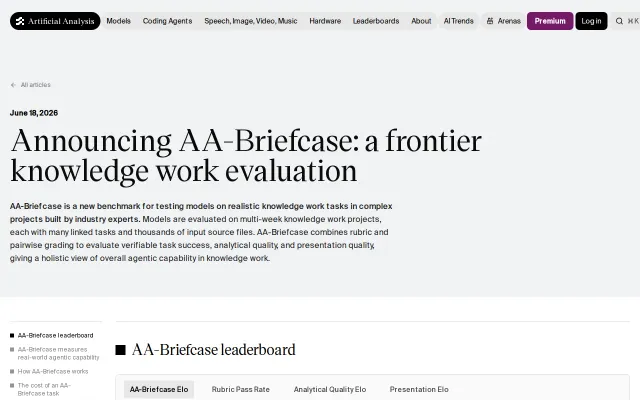
Multi-week project evals beat single-task benchmarks for measuring real agentic capability.