AI/ML●●Solid
Selora – local model for Home Assistant
Four task-specific LoRA adapters for Home Assistant when cloud LLMs raise privacy concerns.
Niche GemCozy
bayshark
744d ago
Granite Switch — Build AI models like you build software
Composing multiple LoRA adapters into one checkpoint solves the model sprawl nightmare.
ML engineers and LLM infrastructure teams
LoRA · Hugging Face PEFT · vLLM
The idea is to get the accuracy benefits of multiple fine-tuned models without having to deploy and maintain a separate model for every task. It adds control tokens and a small switch layer that decides which adapter weights to apply, so different capabilities can be activated inside one model.
The composed model is designed to work with Hugging Face and vLLM, and the project includes ready-to-use adapters and pre-composed Granite Switch models.
Repo: https://github.com/generative-computing/granite-switch
Four task-specific LoRA adapters for Home Assistant when cloud LLMs raise privacy concerns.
3.59ms for 100 LoRA adapters with zero HBM writes—genuine GPU wizardry.
Yet another GitOps tool, but pure Go without shell execution is a nice touch.
LLM cost routing with LoRA awareness when LiteLLM already handles basic proxying.
Stores memory in LoRA weights instead of cache, but lacks working benchmarks.
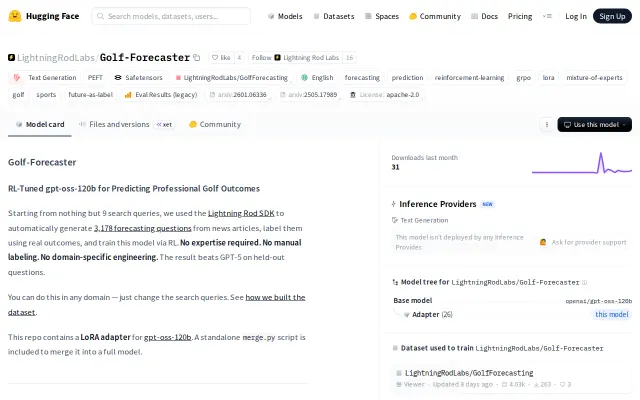
Beats GPT-5 at golf forecasting via auto-labeled data pipeline; replicable recipe for any domain via SDK.