AI/ML●●●Banger
LiteParse, a fast open-source document parser for AI agents
Beats PyPDF and MarkItDown on accuracy without needing GPUs or cloud APIs.
Solve My ProblemSlickCrowd Pleaser
freezed8
1202mo ago
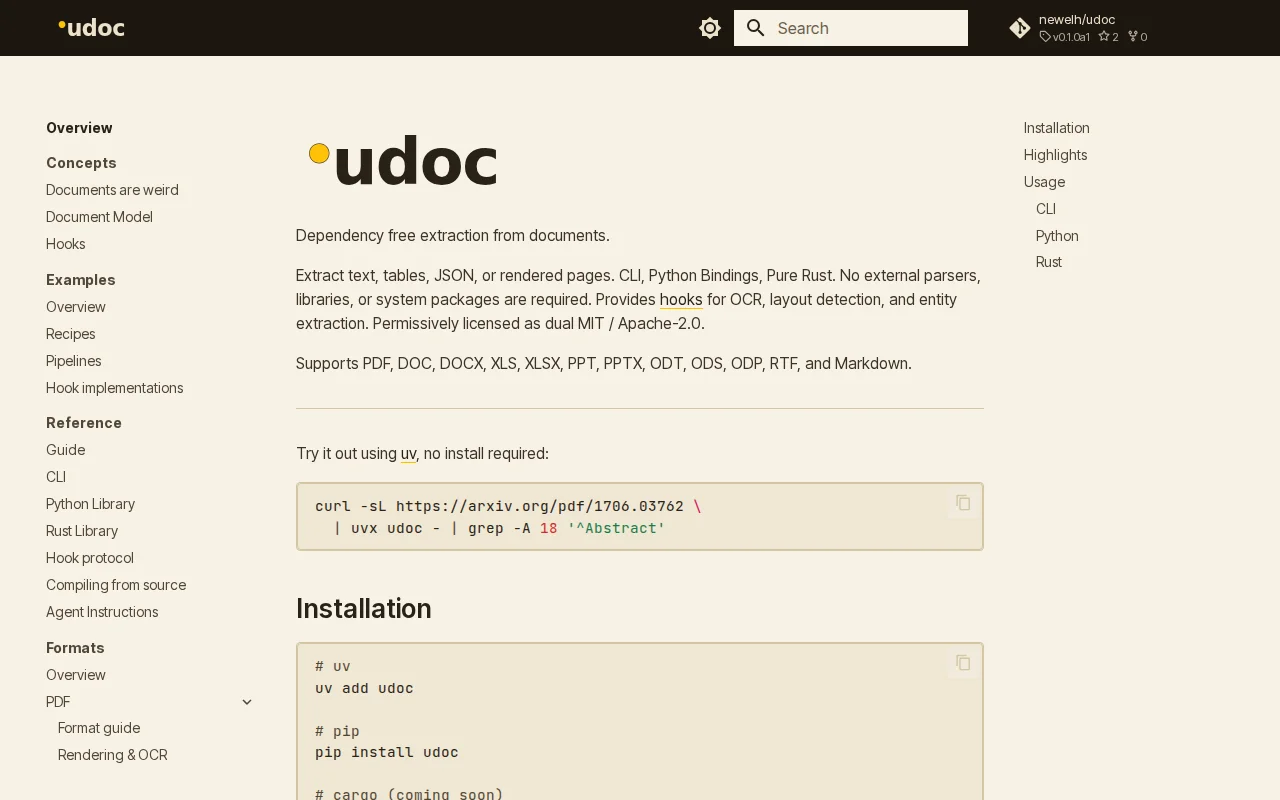
Pure Rust parsers for legacy Office formats with zero external dependencies.
Backend engineers building document processing pipelines
Apache Tika · Pandoc · Poppler
Beats PyPDF and MarkItDown on accuracy without needing GPUs or cloud APIs.
Pure-Rust DOCX to PDF converter running 100x faster than LibreOffice with zero C dependencies.
Six data models in one binary, but no proof of production use or comparison benchmarks.
Preserves document structure instead of flattening to text like most RAG tools.
ProofPudding returns extraction results with explicit links back to the exact page and source text, supports native and scanned PDFs plus DOCX/images, and ships Python/TypeScript SDKs — handy for agents that need auditable facts. It’s a pragmatic product (per-extraction pricing and confidence scores are nice), but the market is crowded; I want clarity on underlying models, real-world accuracy numbers, and how it compares to Document AI/Textract in edge cases.
Provenance-first RAG beats anonymous text chunks, but Cursor and Continue already own this space.