Productivity●●●Banger
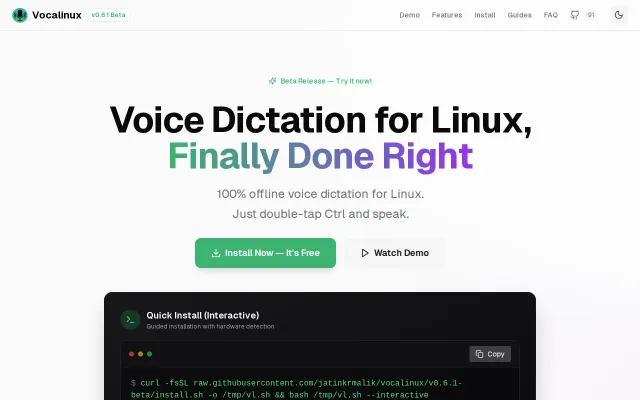
Vocalinux // 100% offline voice typing for Linux
Linux finally gets offline voice typing; Ctrl-tap + Vulkan GPU support vs cloud-dependent alternatives.
Solve My ProblemDark Horse
jatinkrmalik
404mo ago
Multi-GPU prefill acceleration for llama.cpp
2x prefill speedup on 12k+ token contexts by treating GPUs like a production line.
Multi-GPU LLM inference operators and llama.cpp users
llama.cpp · vLLM · TGI
Linux finally gets offline voice typing; Ctrl-tap + Vulkan GPU support vs cloud-dependent alternatives.
Useful tutorial, but llama.cpp docs and Ollama already cover most of this.
Shard-based scheduling cuts GPU wait time, though Ray Tune offers similar early stopping.
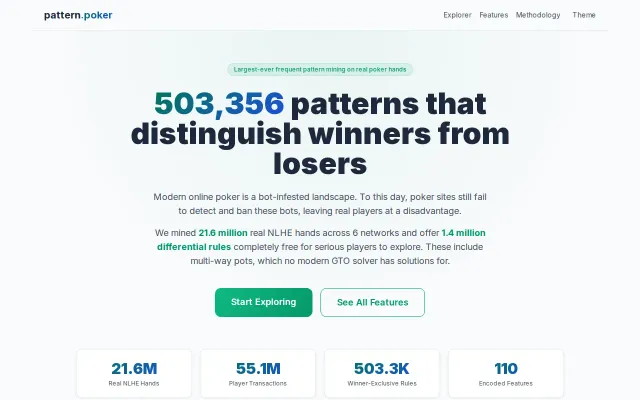
GPU-accelerated pattern mining from protein research repurposed for poker hand analysis.
Panama FFM beats JNI for in-process llama.cpp - no sidecar, no HTTP, no native install.
Finally one CLI for Ollama, llama.cpp, and vLLM instead of three separate tools.