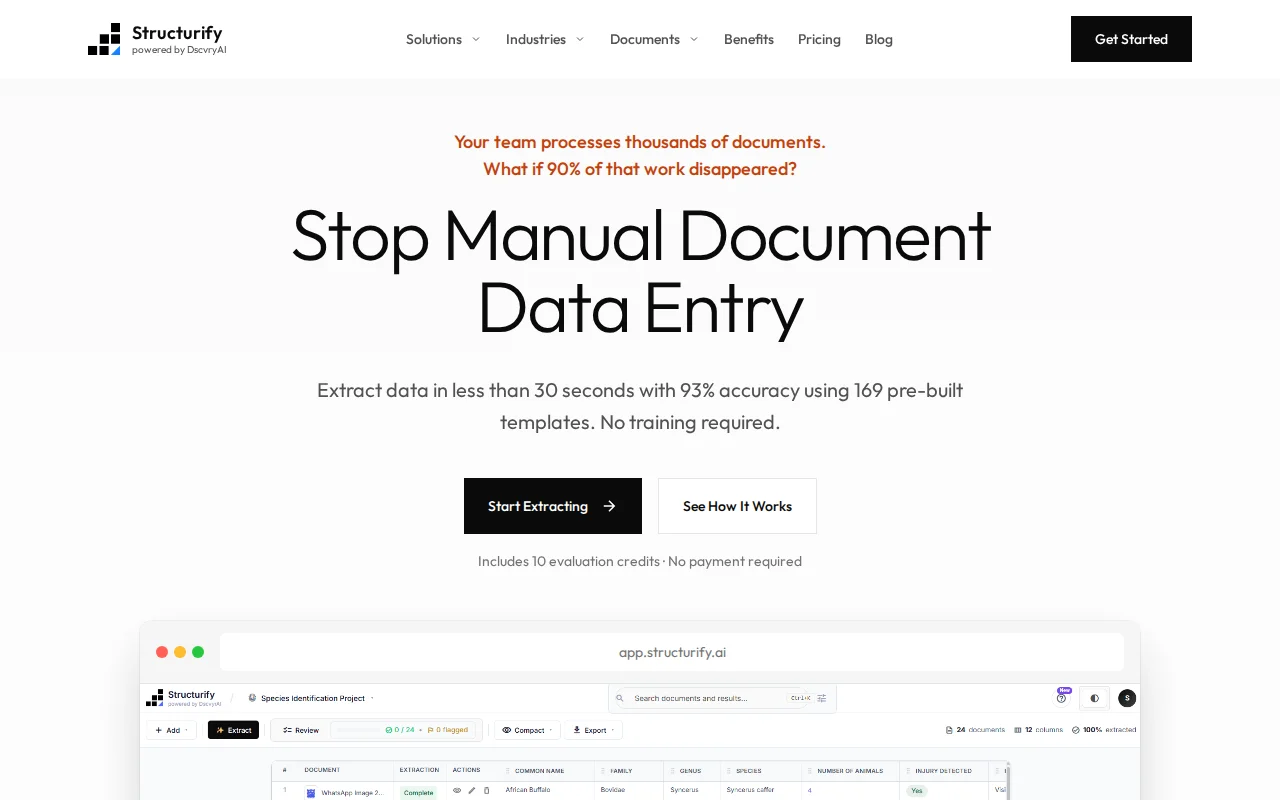
Hey HN! we built Structurify (
https://structurify.ai) to solve a problem we kept hitting at our AI consultancy: enterprises drowning in unstructured documents that need to become structured data.
The typical approach is OCR + custom ML pipelines, which takes months to build and degrades on anything that isn't a clean PDF. We took a different approach — contextual AI understanding instead of character-level OCR.
What it does: Upload any document (PDF, scan, photo, Word, Excel, PowerPoint) → describe what you want extracted in plain English → get structured JSON/CSV in ~30 seconds. 93%+ accuracy.
We have 169 pre-built extraction templates (SDS, invoices, medical records, W-9s, construction pay apps, etc.) but you can also describe custom extractions without any template.
Some things we're proud of:
Multi-page understanding (connects data across 50+ page documents)
Multi-language (30+ languages)
Confidence scoring with human-in-the-loop review
Full REST API, webhook support, most integrations done in a day
$0.20/extraction, no subscription, credits never expire
Curious what HN thinks. Happy to answer technical questions about the architecture.
Free trial: 50 credits with work email, no CC required.