AI/ML●●●Banger
Pencil Puzzle Bench – LLM Benchmark for Multi-Step Verifiable Reasoning
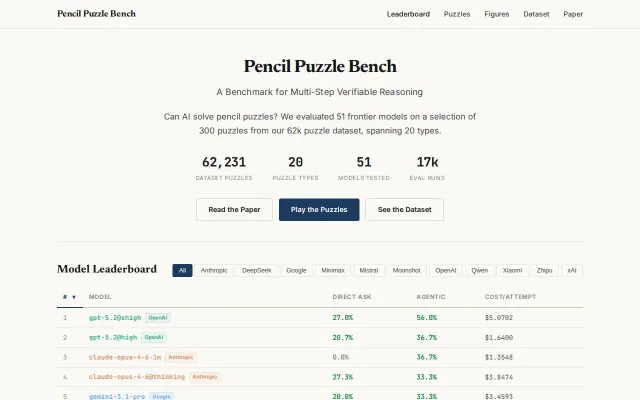
62k puzzle benchmark reveals reasoning depth, cost variance, and stark US vs China model gaps.
Big BrainCrowd PleaserSolve My Problem
bluecoconut
503mo ago
LLM benchmark for datetime format generation reliability
RFC 3339 hits 88% accuracy while unix epoch fails 50% of the time.
AI engineers building production LLM applications
TimeBench · TRAM · HELM
* If you need an LLM to parse OR emit a timestamp, use:
RFC 3339 ( e.g. 2024-03-26 10:30:00-05:00 )
* python date format also works well* Do NOT use unix epoch or javascript date formats.
* Smaller models and non-reasoning models still make a LOT of mistakes in time parsing / formatting.
---
There are lots of temporal reasoning benchmarks (like TimeBench, TRAM, etc.) but they test whether models understand time concepts. Nothing on which datetime output format models get right most often. So we just built the benchmark ourselves.
We tested 22 models across Google, Anthropic, OpenAI, Qwen, and GLM on 235 scenarios and 7 different formats.
The two that surprised us the most were JavaScript Date and unix epoch. JavaScript Date is probably the most commonly used format and it's wrong ~1 in 4 times on parsing. Unix epoch drops to 40% on arithmetic tasks. If you need epoch, just have the model output a string and convert it yourself in code.
62k puzzle benchmark reveals reasoning depth, cost variance, and stark US vs China model gaps.
Using 1980s Rogue as an LLM benchmark is genuinely novel and technically clever.
Unsupervised bug benchmark using agents as both attackers and defenders—novel scoring methodology.
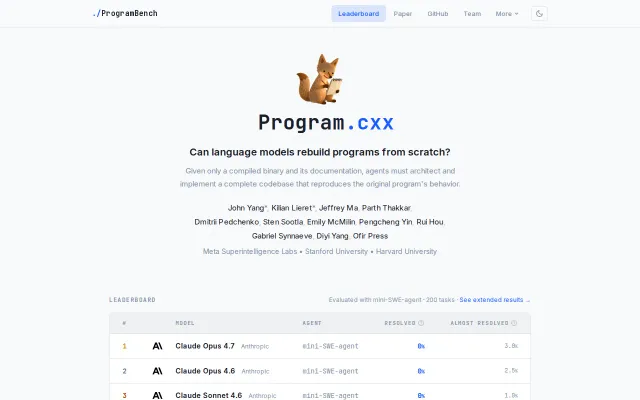
Agents fail completely at rebuilding binaries from scratch without source code.
Audited LoCoMo and found 6.4% of answer keys are wrong—benchmarks are broken.
Transparent benchmark for data analysis LLMs with verifiable notebook artifacts.