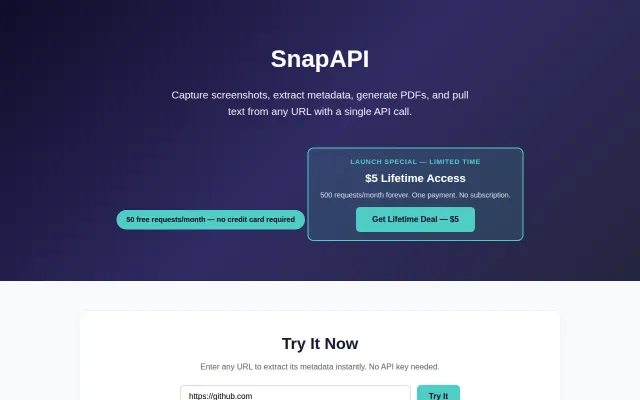
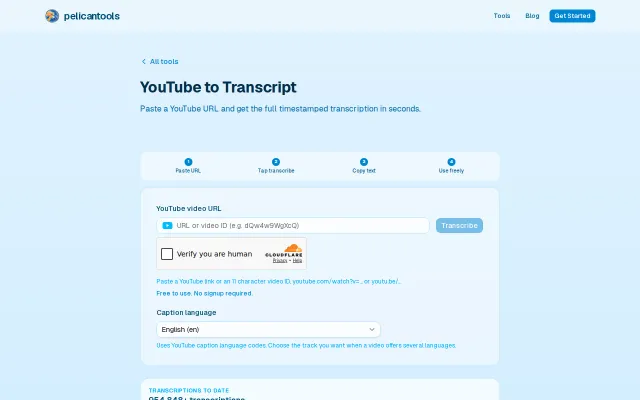
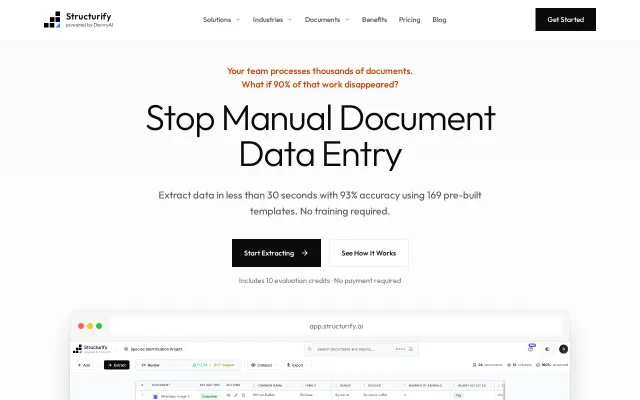
Productivity●●Solid
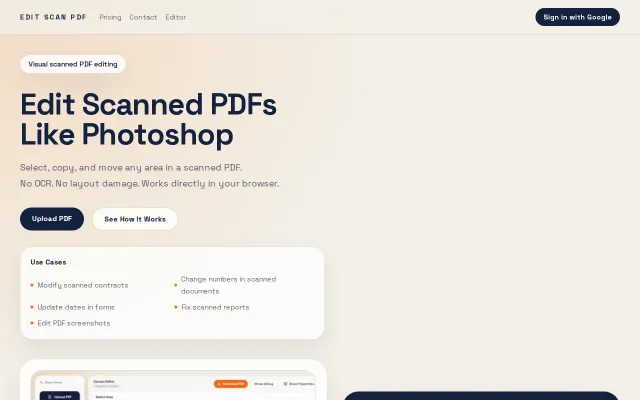
Edit scanned PDFs like Photoshop
Edit scanned PDFs visually without OCR, like moving layers in Photoshop.
Solve My ProblemSlick
bai422
343mo ago
OCR for PDFs is useful, but Adobe and Google Drive already do this for free.
Researchers, students, and knowledge workers dealing with PDF archives
Adobe Acrobat · Google Drive · OnlineOCR.net
Edit scanned PDFs visually without OCR, like moving layers in Photoshop.
Yet another screenshot API competing with ApiFlash and ScreenshotAPI.
Yet another YouTube transcript tool—dozens of free alternatives already exist.
Noise-filtered PDF/web extraction for RAG, but already solved by Jina, Firecrawl.
LLM infers schema once, Go does 10k-row extraction—avoids token waste.
93% accuracy document extraction, but remove.bg-style competition already exists.